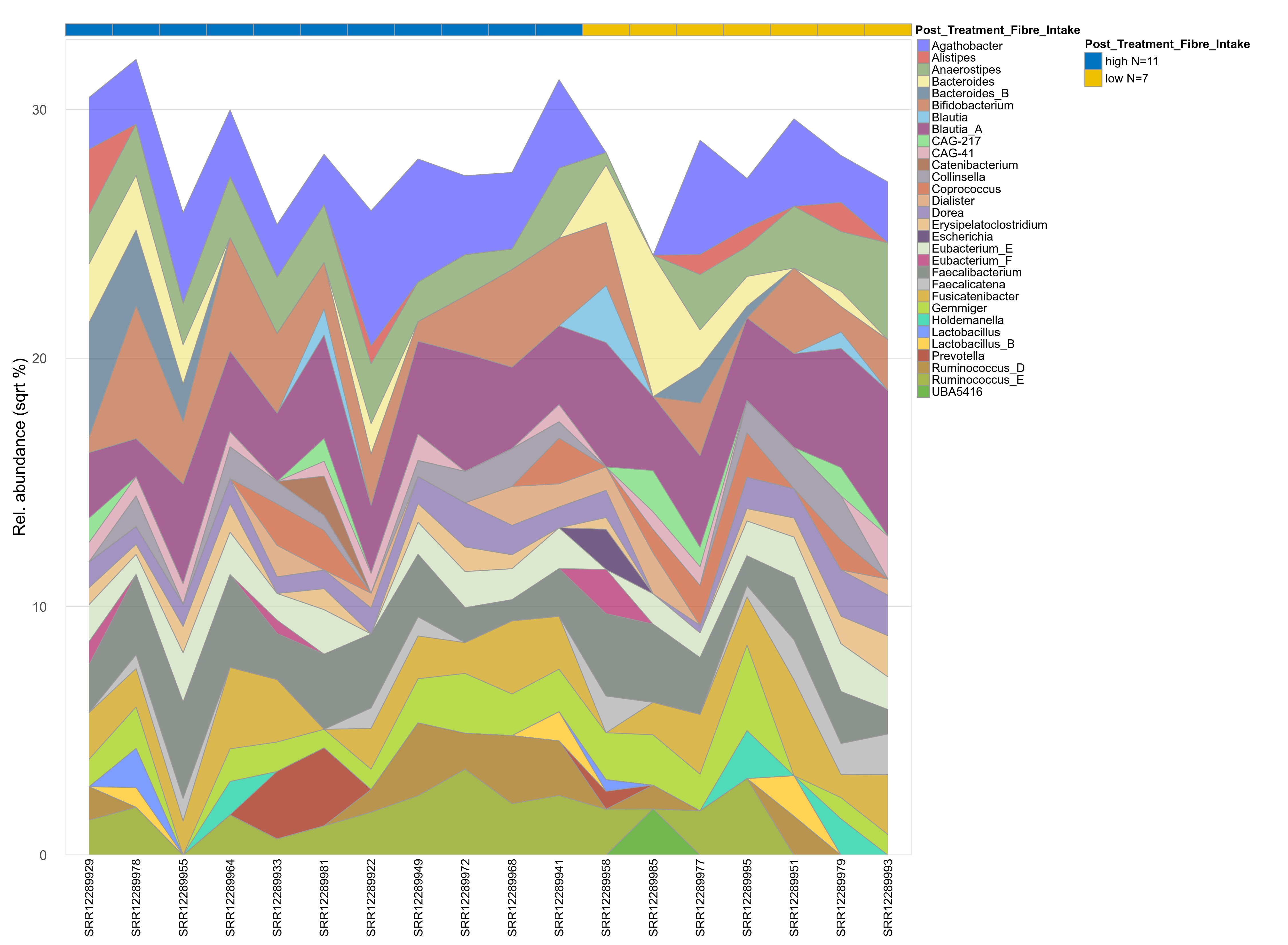
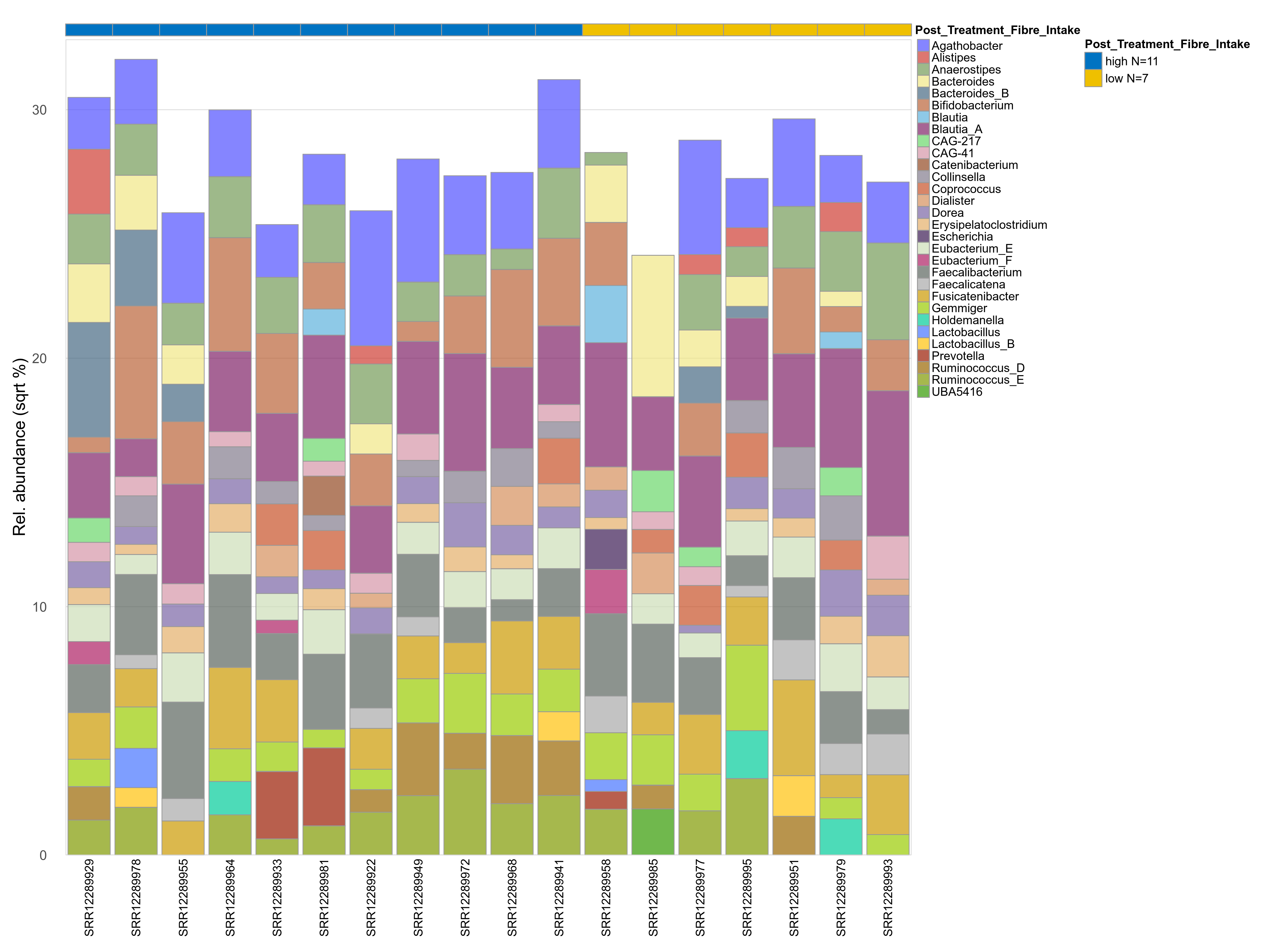
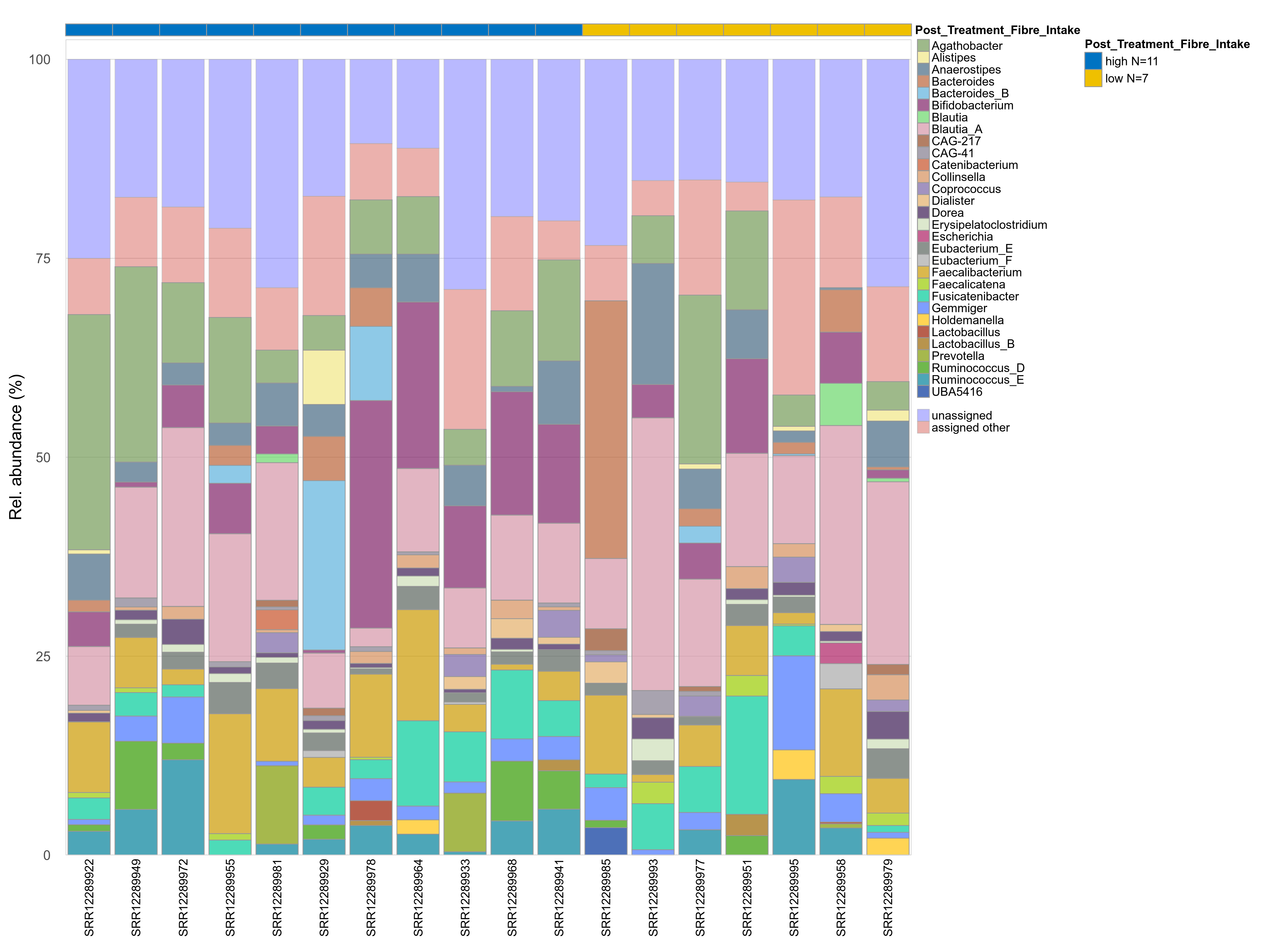
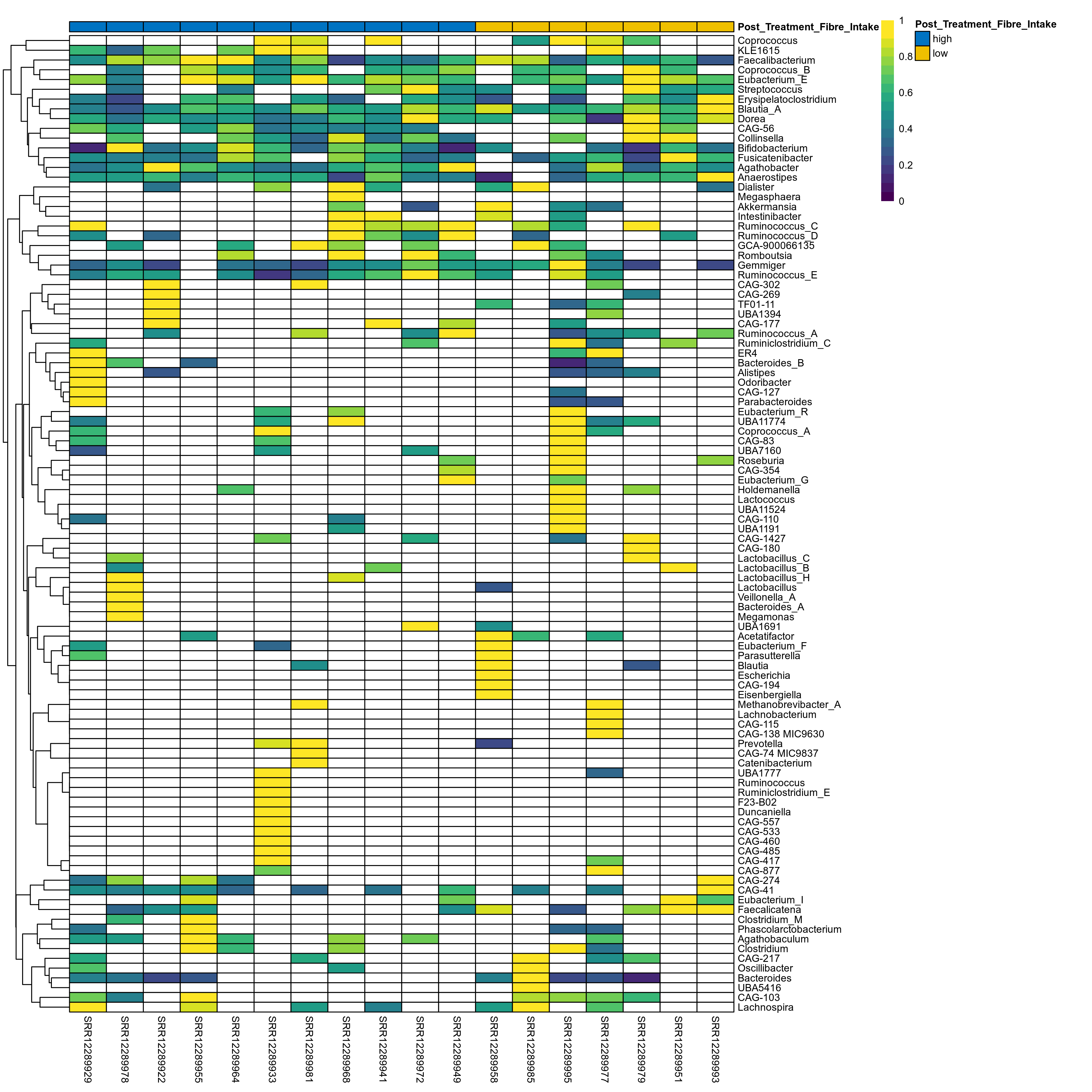
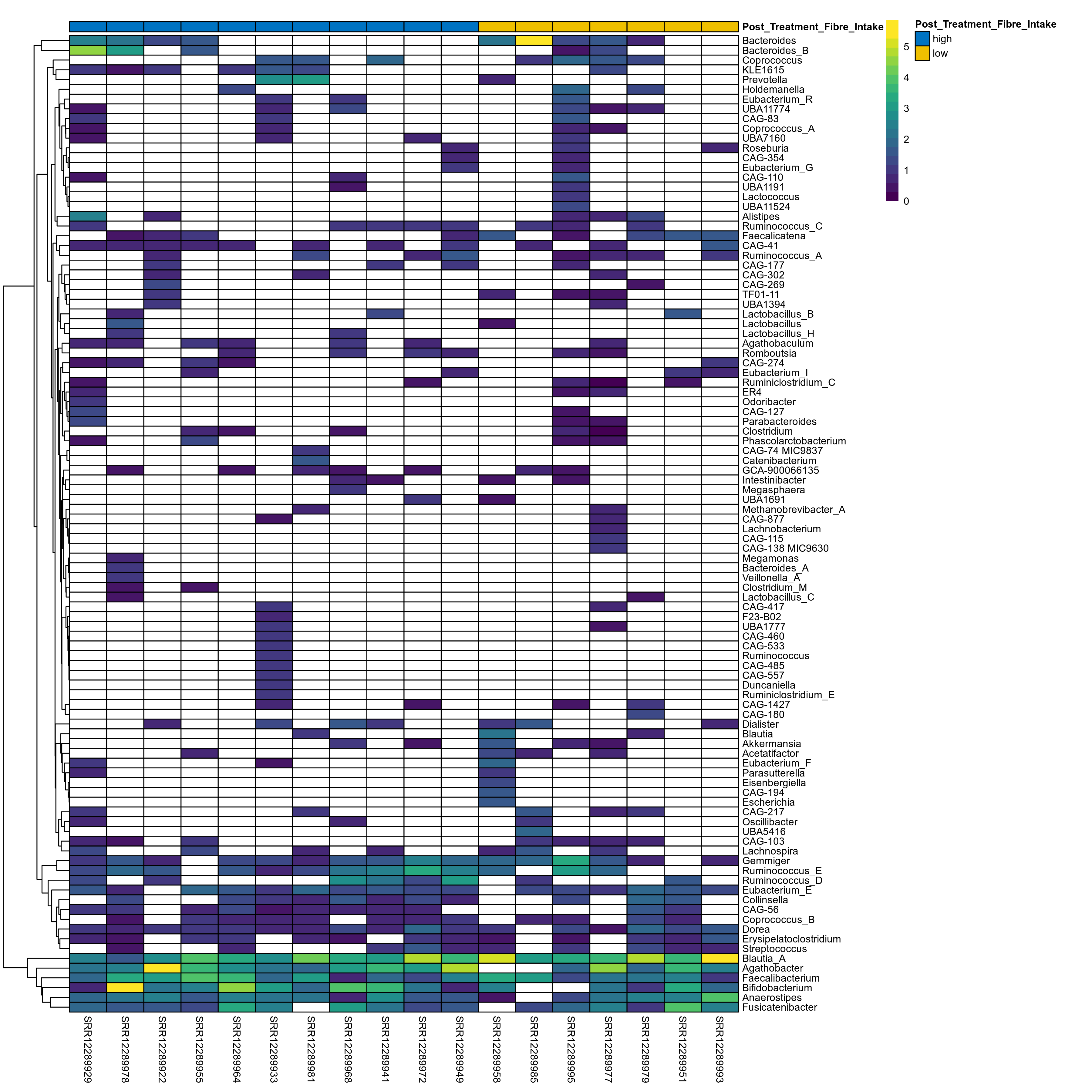
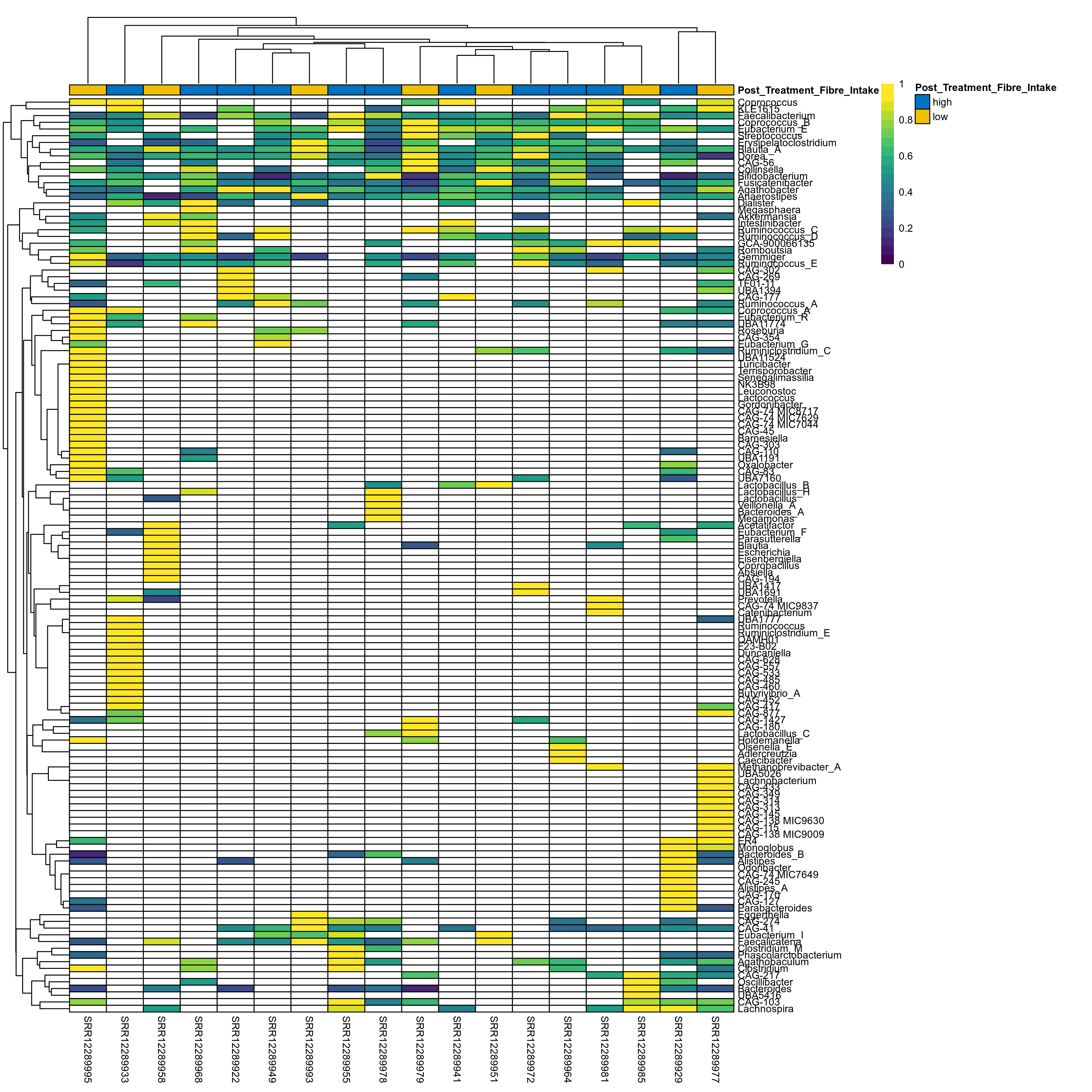
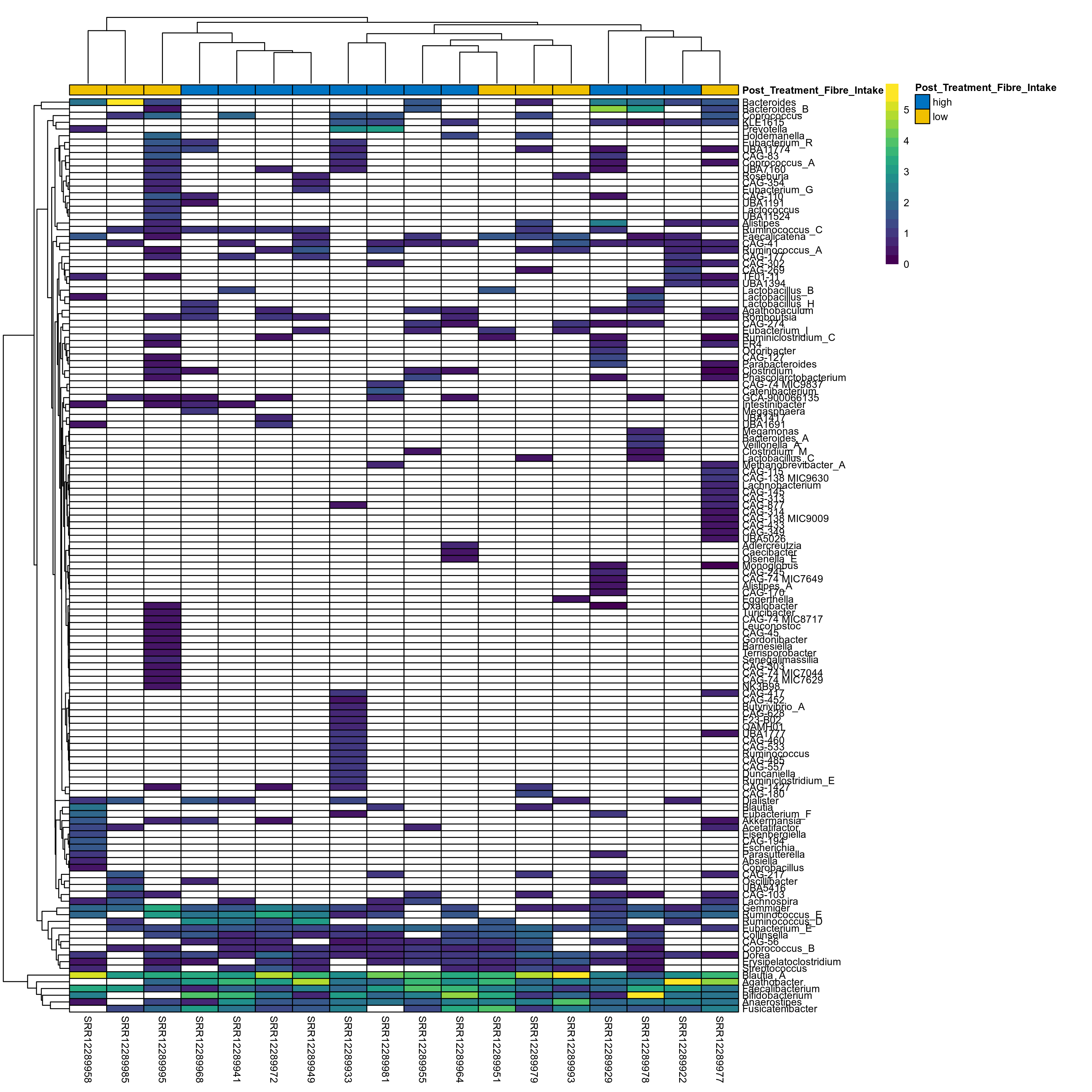
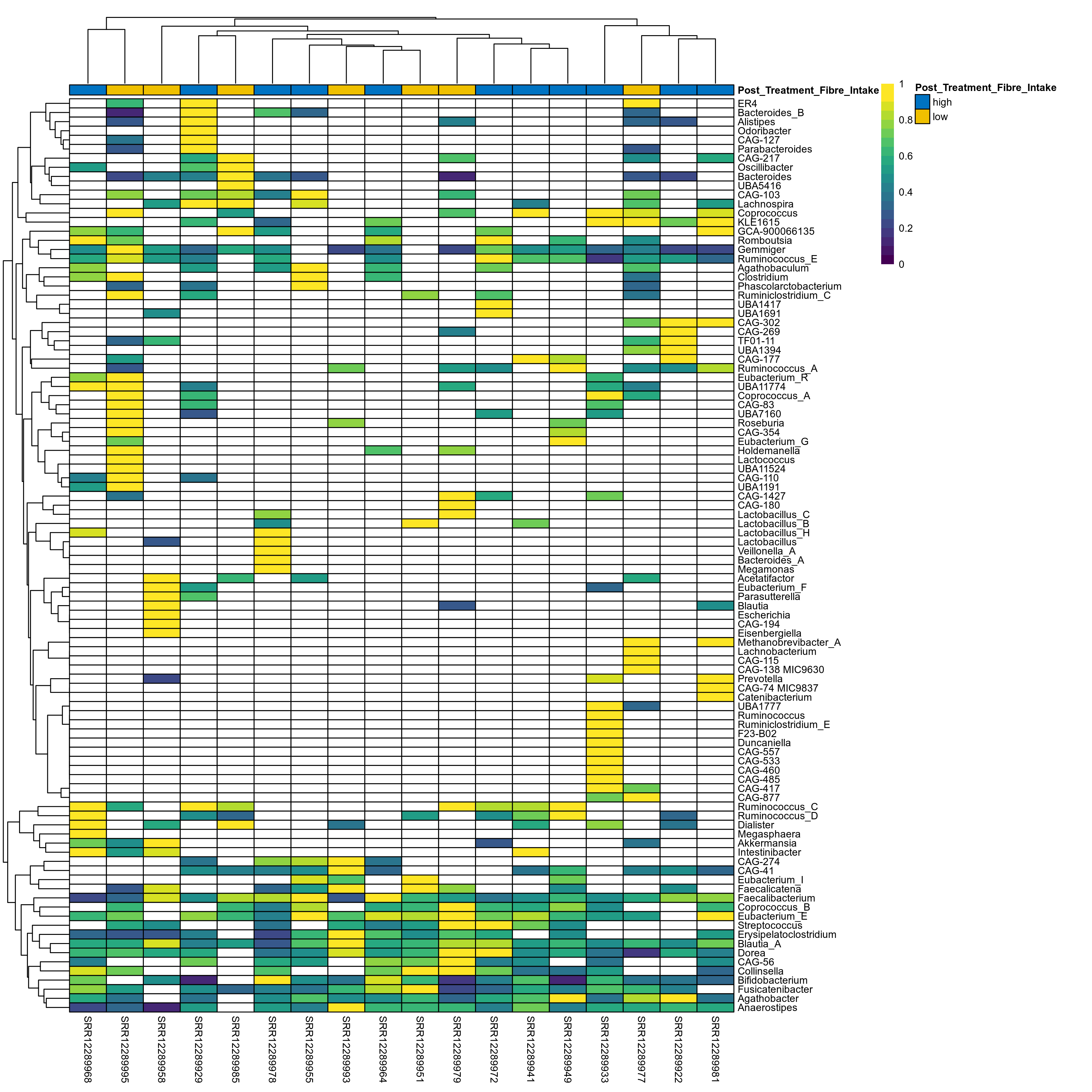
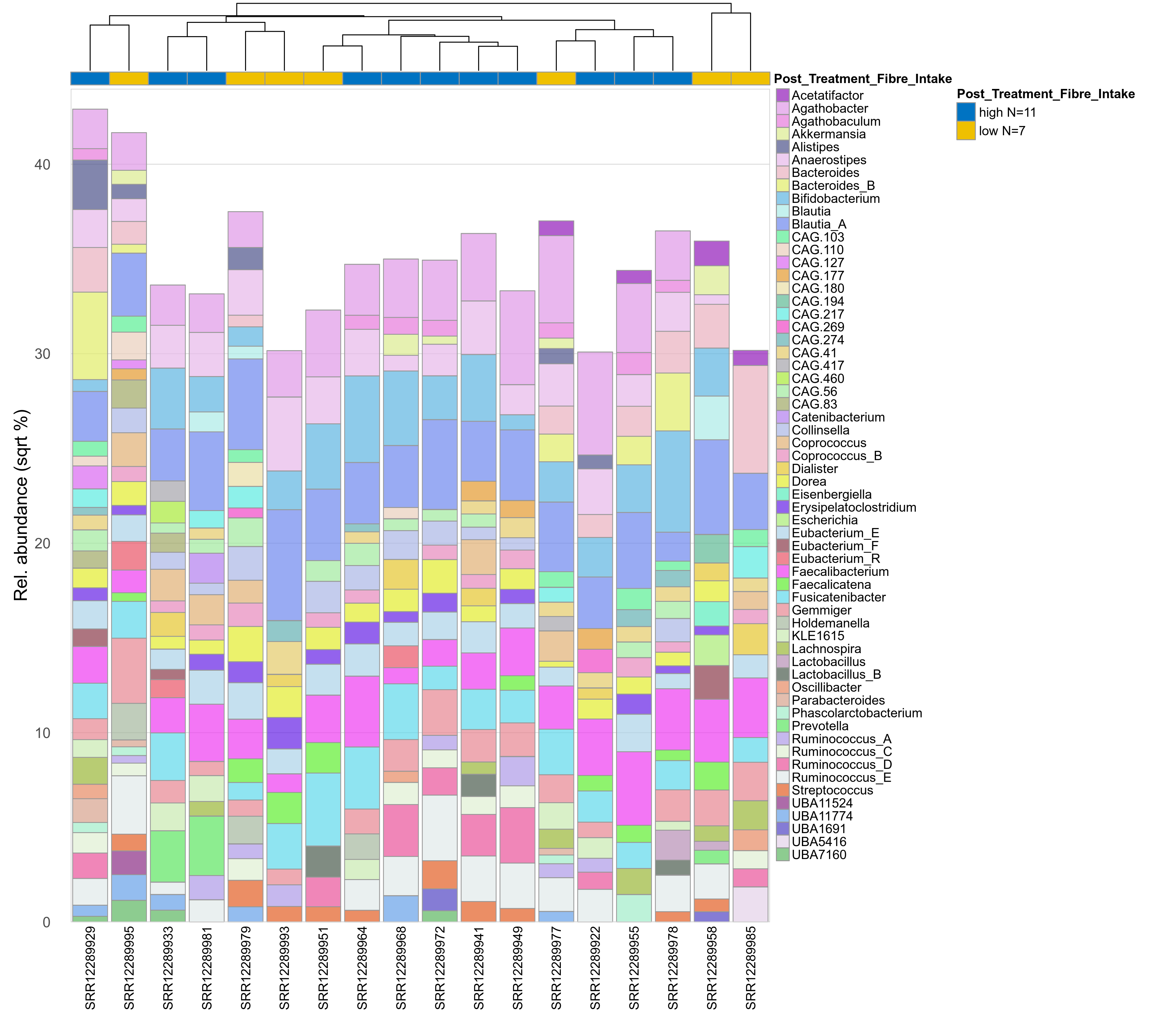
The charts below show the taxonomic composition of the analysed samples using different quantitative visualization techniques. Only the top most abundant genera are shown.
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
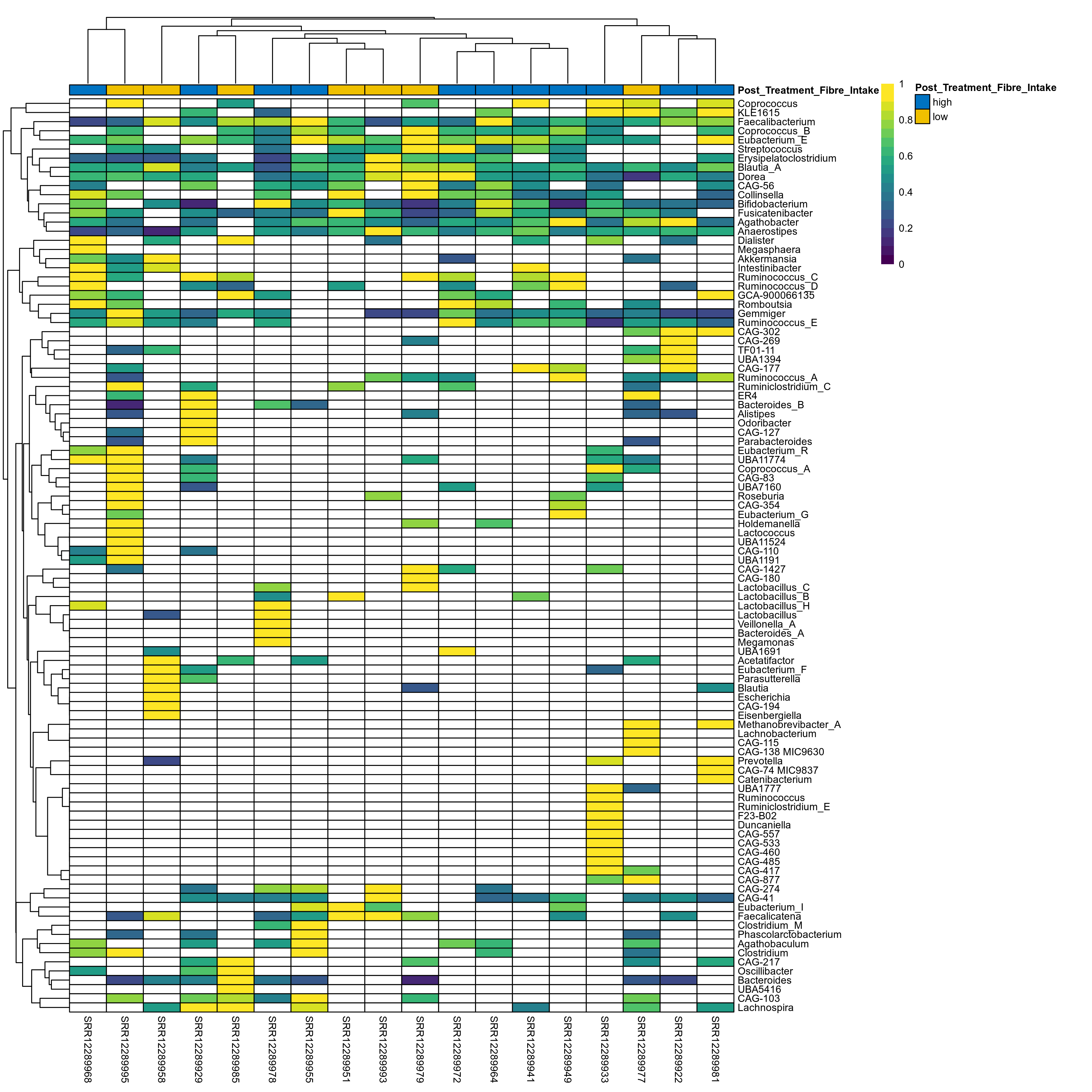
Click here to open full-sized image in new window.
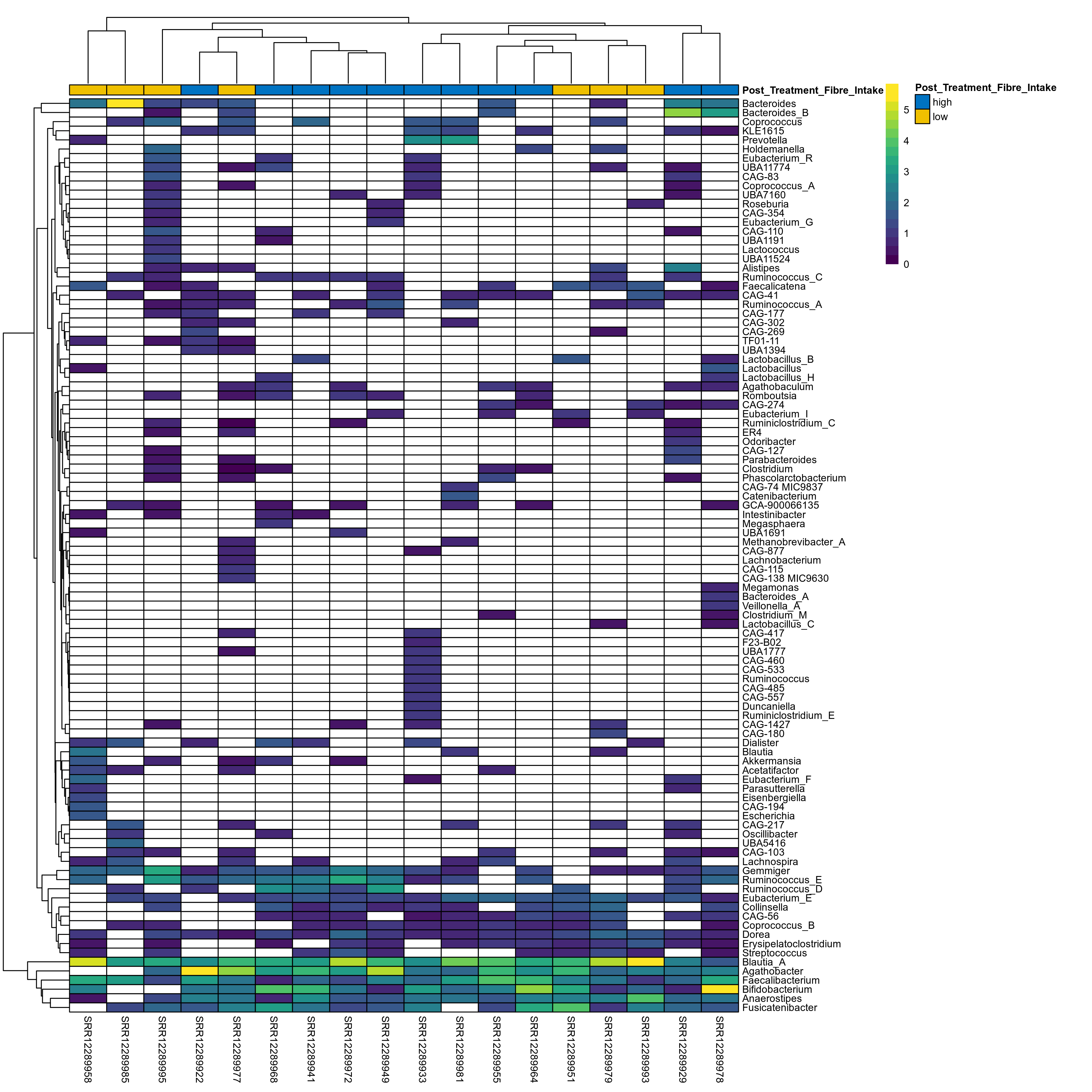
Click here to open full-sized image in new window.
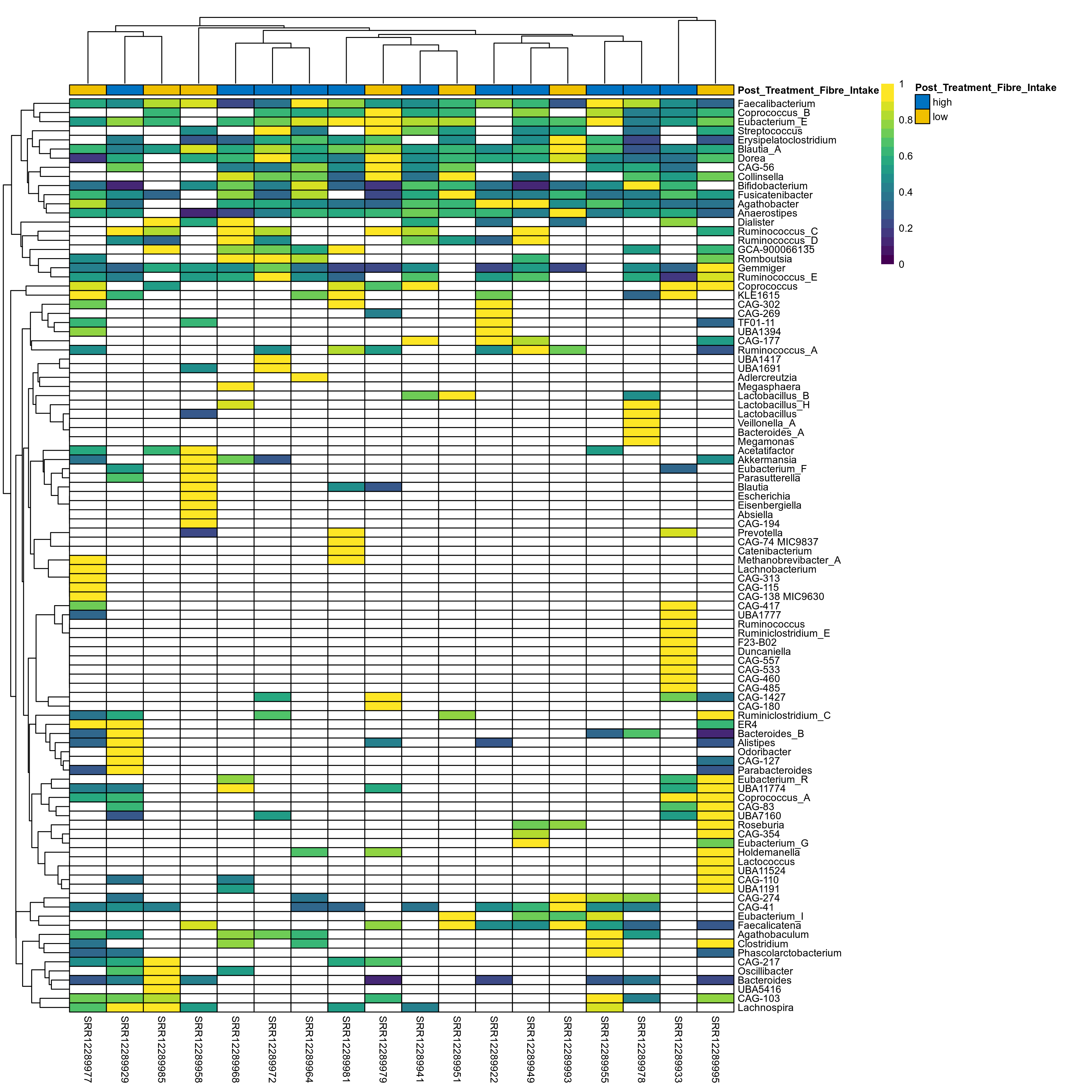
Click here to open full-sized image in new window.
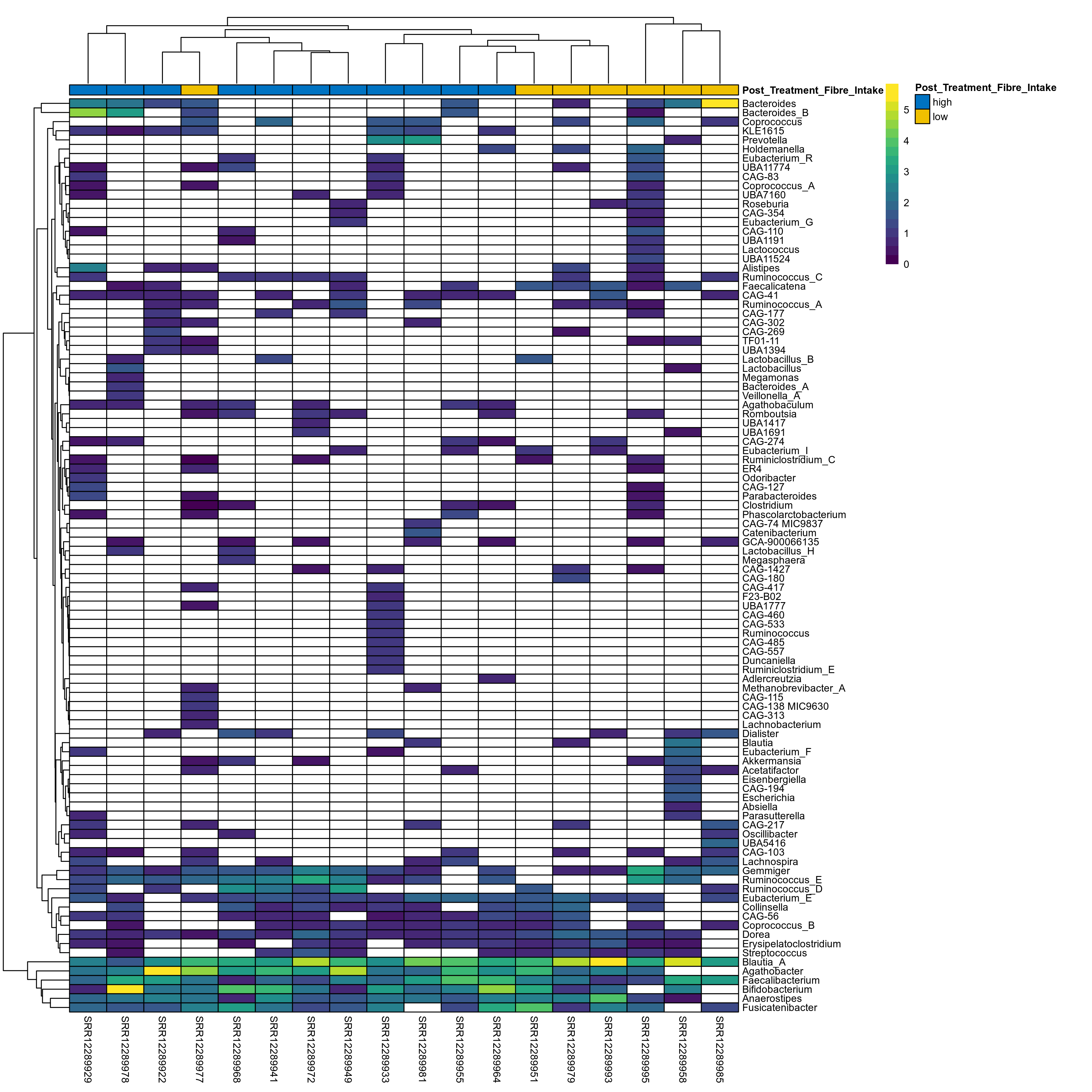
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
Click here to open interactive barchart in new window.
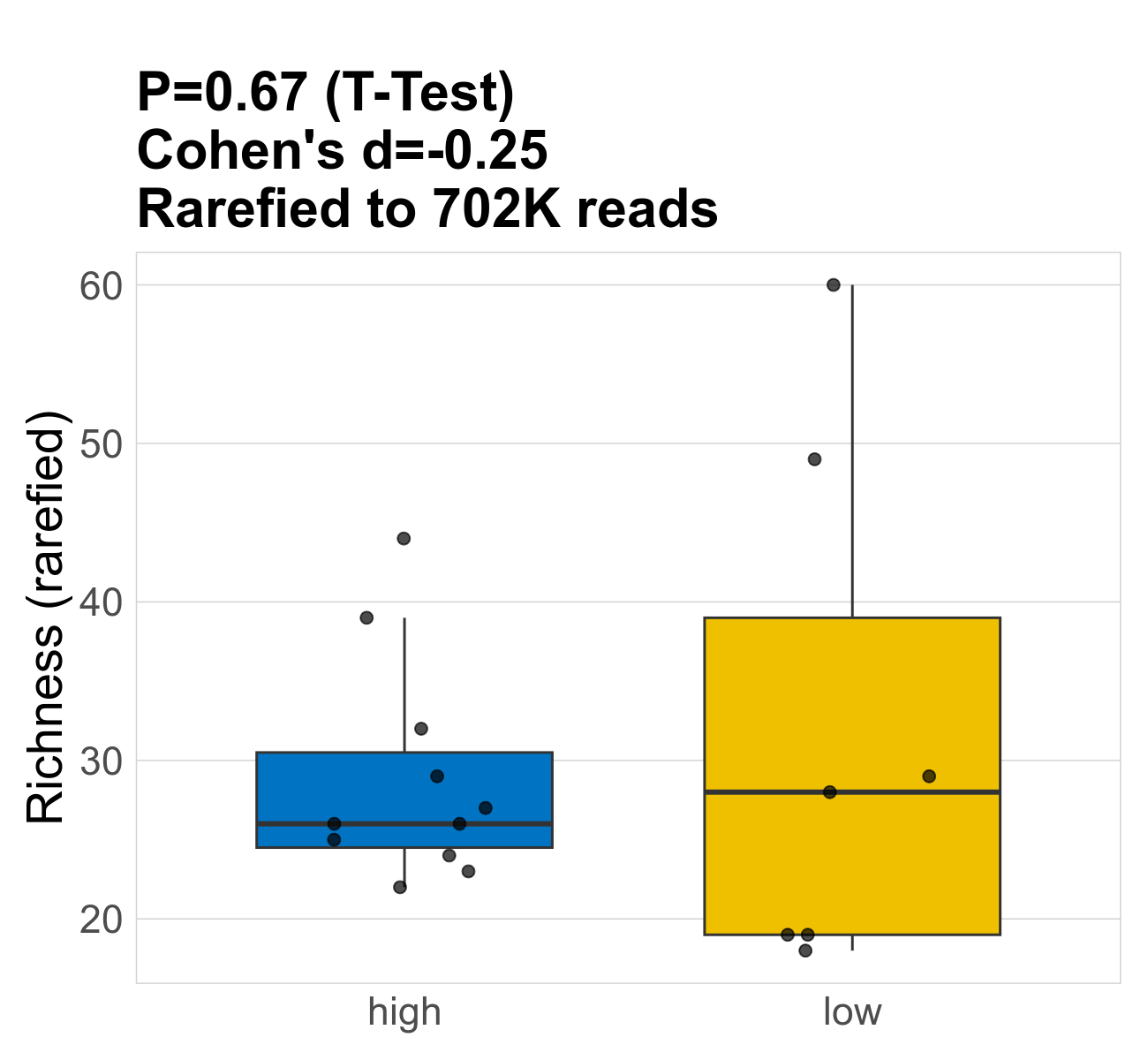
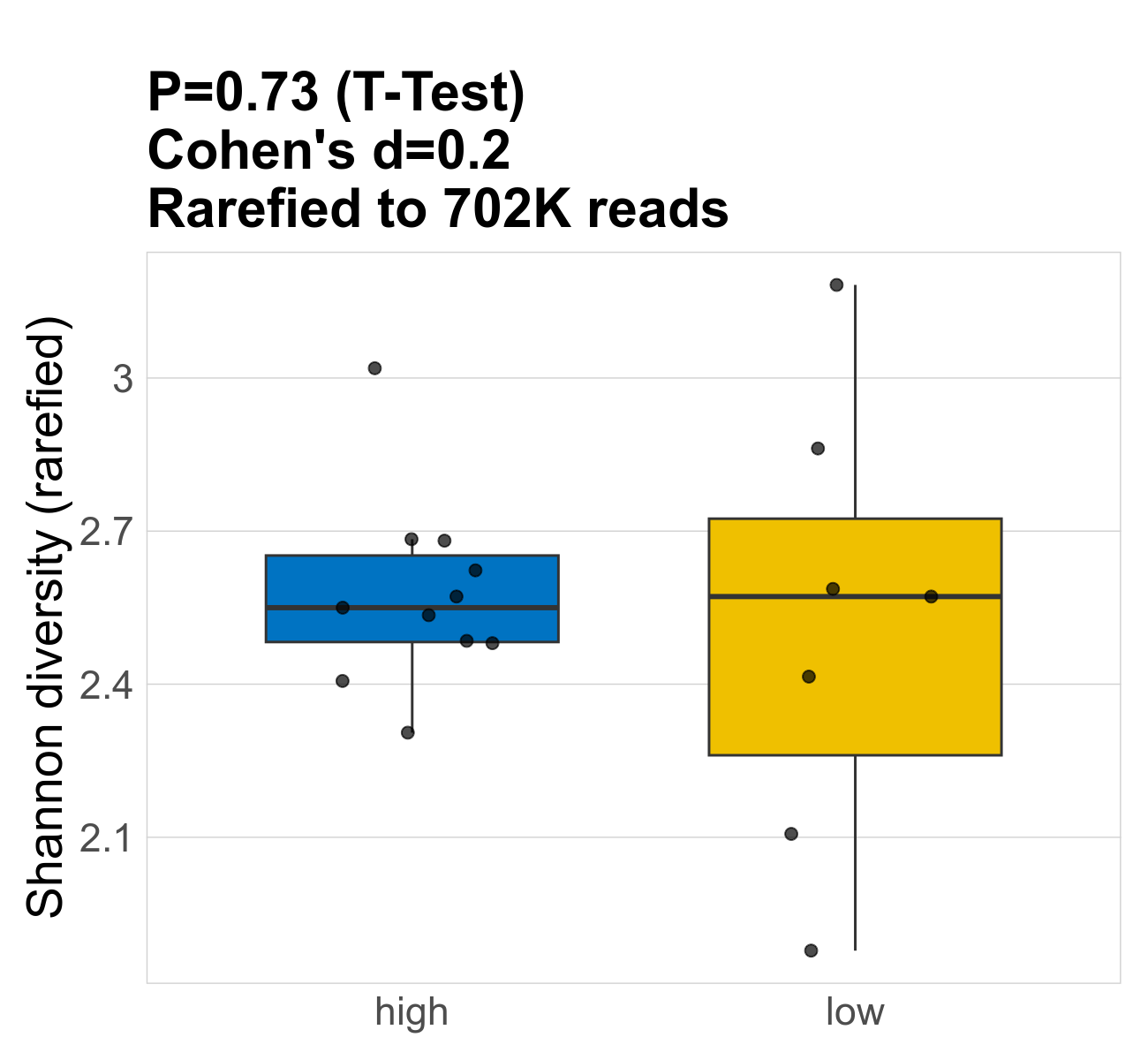
This page provides an overview of the microbial alpha diversity of the analysed samples. Alpha diversity is measured by the Shannon index and species richnes. Richness simply quantifies the total number of genera present in each sample. Shannon index additionally accounts for relative abundance and evenness of the genera present and quantifies the entropy of microbial communties. Barcharts and boxplots present the mean diversity in each study group.
| Index | rarefiedTo | P Welch's t-test | Mean Pos | Mean Abundance | Median Abundance | Mean Post_Treatment_Fibre_Intakehigh | Median Post_Treatment_Fibre_Intakehigh | SD Post_Treatment_Fibre_Intakehigh | Mean Post_Treatment_Fibre_Intakelow | Median Post_Treatment_Fibre_Intakelow | SD Post_Treatment_Fibre_Intakelow | Fold Change Log2(Post_Treatment_Fibre_Intakelow/Post_Treatment_Fibre_Intakehigh) | Positive samples | Positive Post_Treatment_Fibre_Intakehigh | Positive Post_Treatment_Fibre_Intakelow | Positive_Post_Treatment_Fibre_Intakehigh_percent | Positive_Post_Treatment_Fibre_Intakelow_percent |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Shannon | 702268 | 0.73 | 2.6 | 2.6 | 2.6 | 2.6 | 2.5 | 0.19 | 2.5 | 2.6 | 0.44 | -0.057 | 18 / 18 (100%) | 11 / 11 (100%) | 7 / 7 (100%) | 1 | 1 |
| Richness | 702268 | 0.67 | 30 | 30 | 26 | 29 | 26 | 6.9 | 32 | 28 | 16 | 0.14 | 18 / 18 (100%) | 11 / 11 (100%) | 7 / 7 (100%) | 1 | 1 |
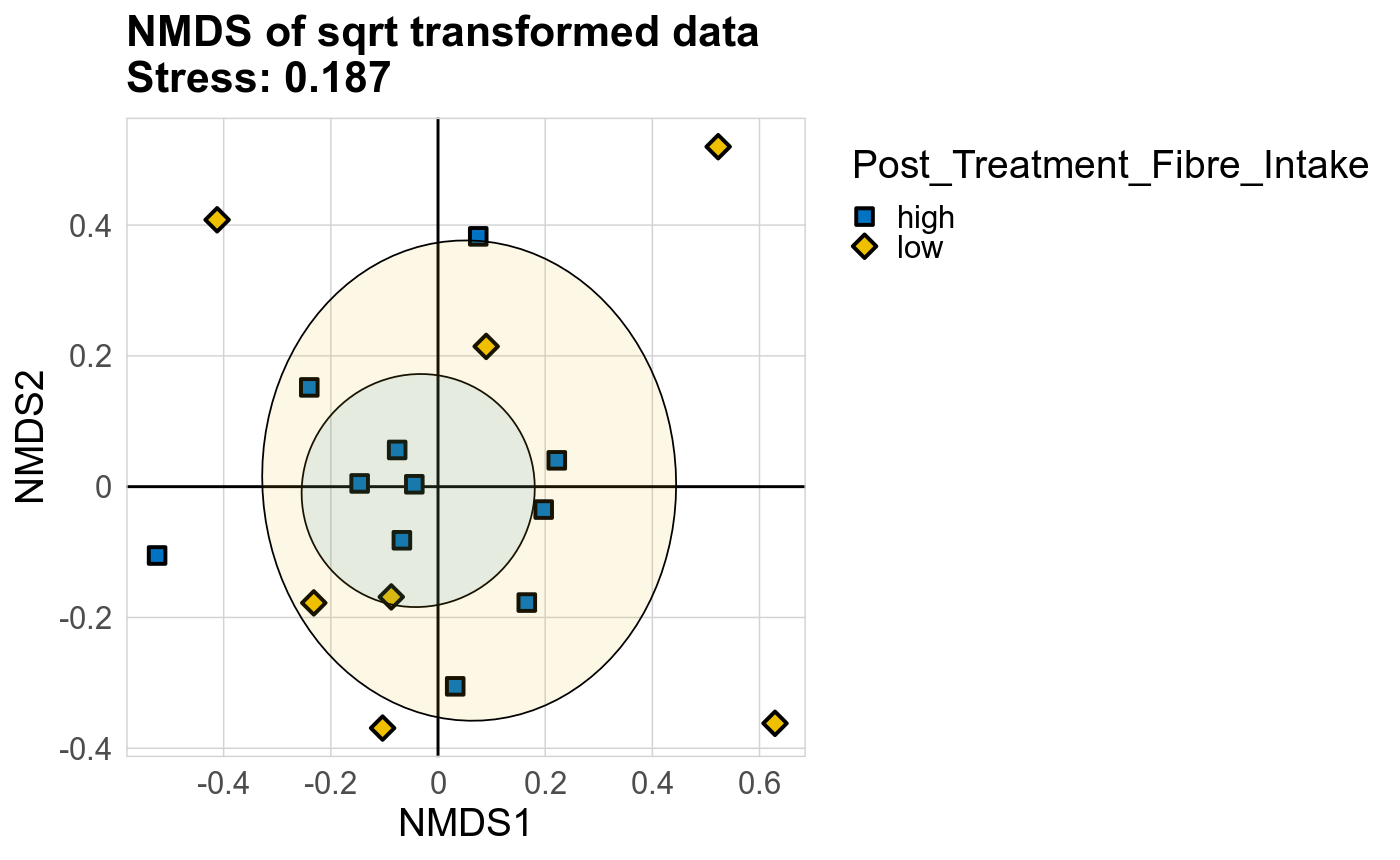
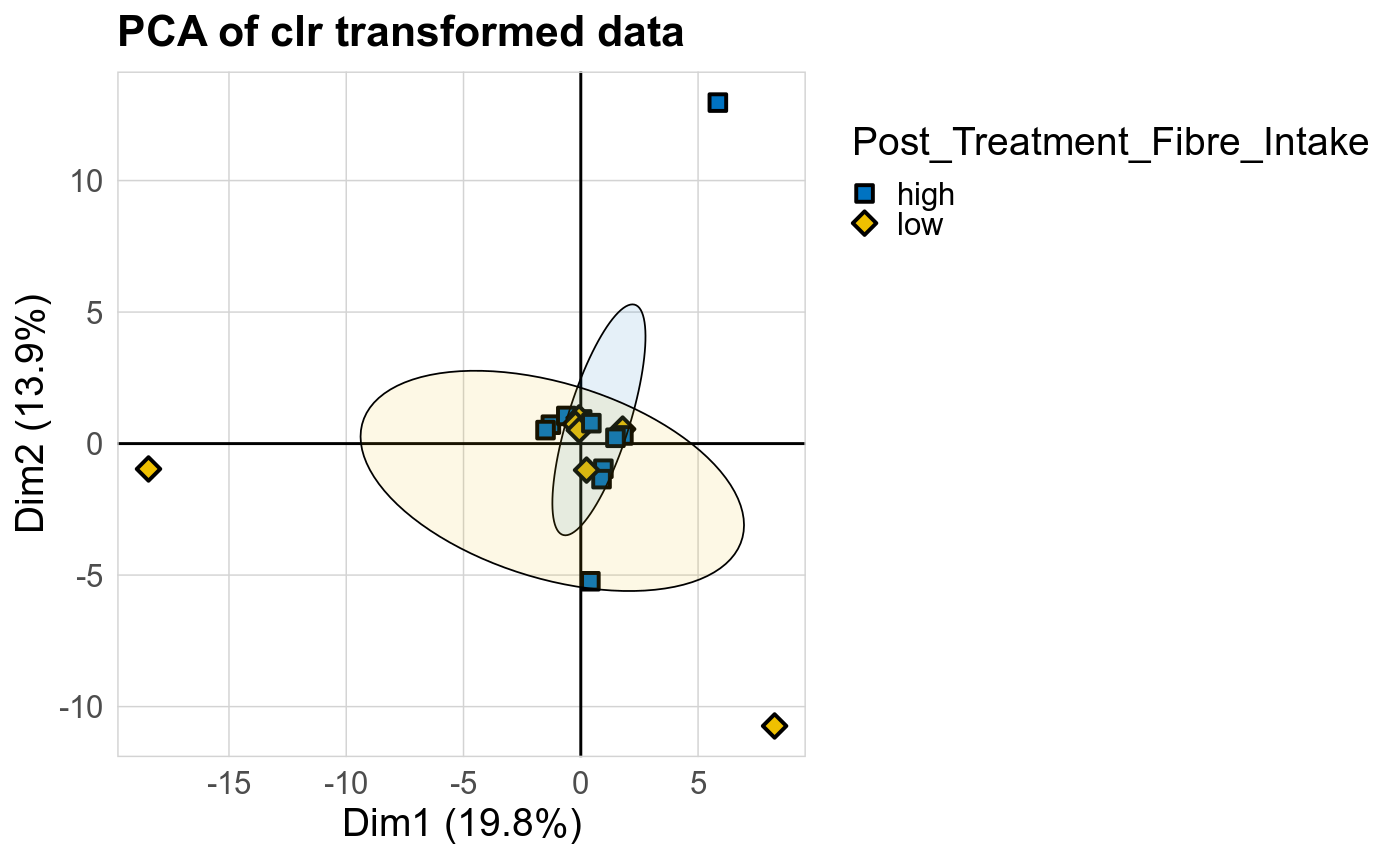
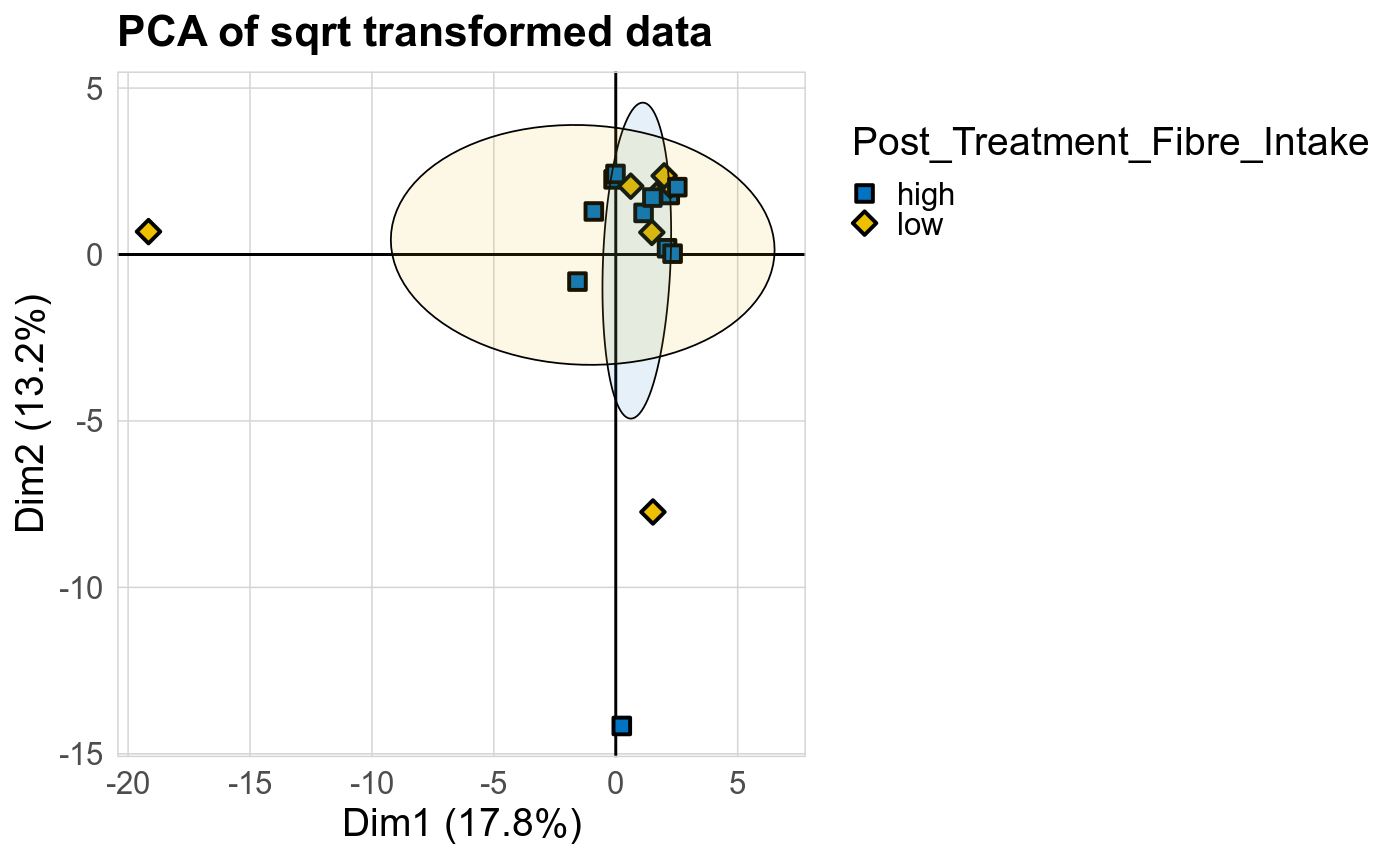
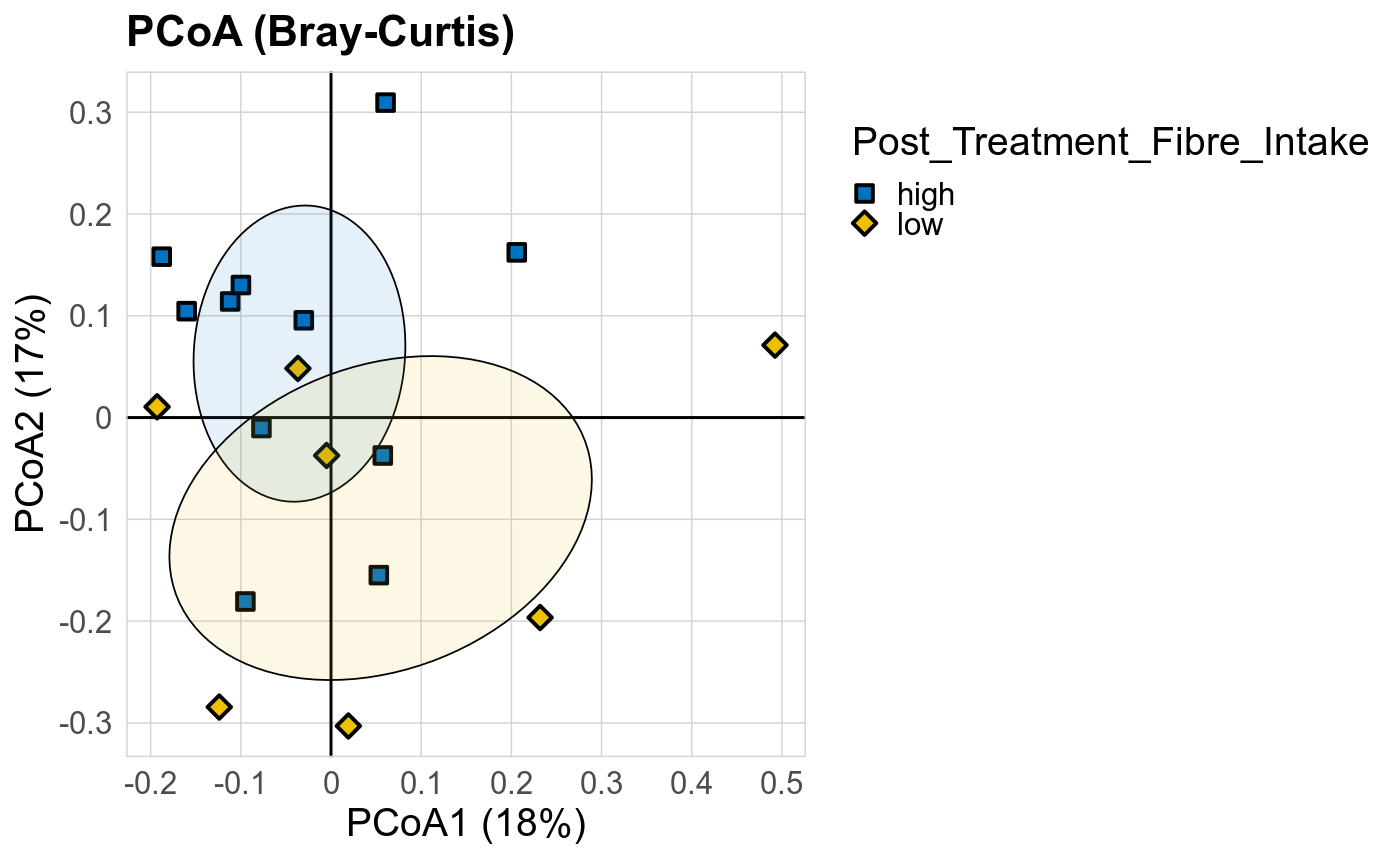
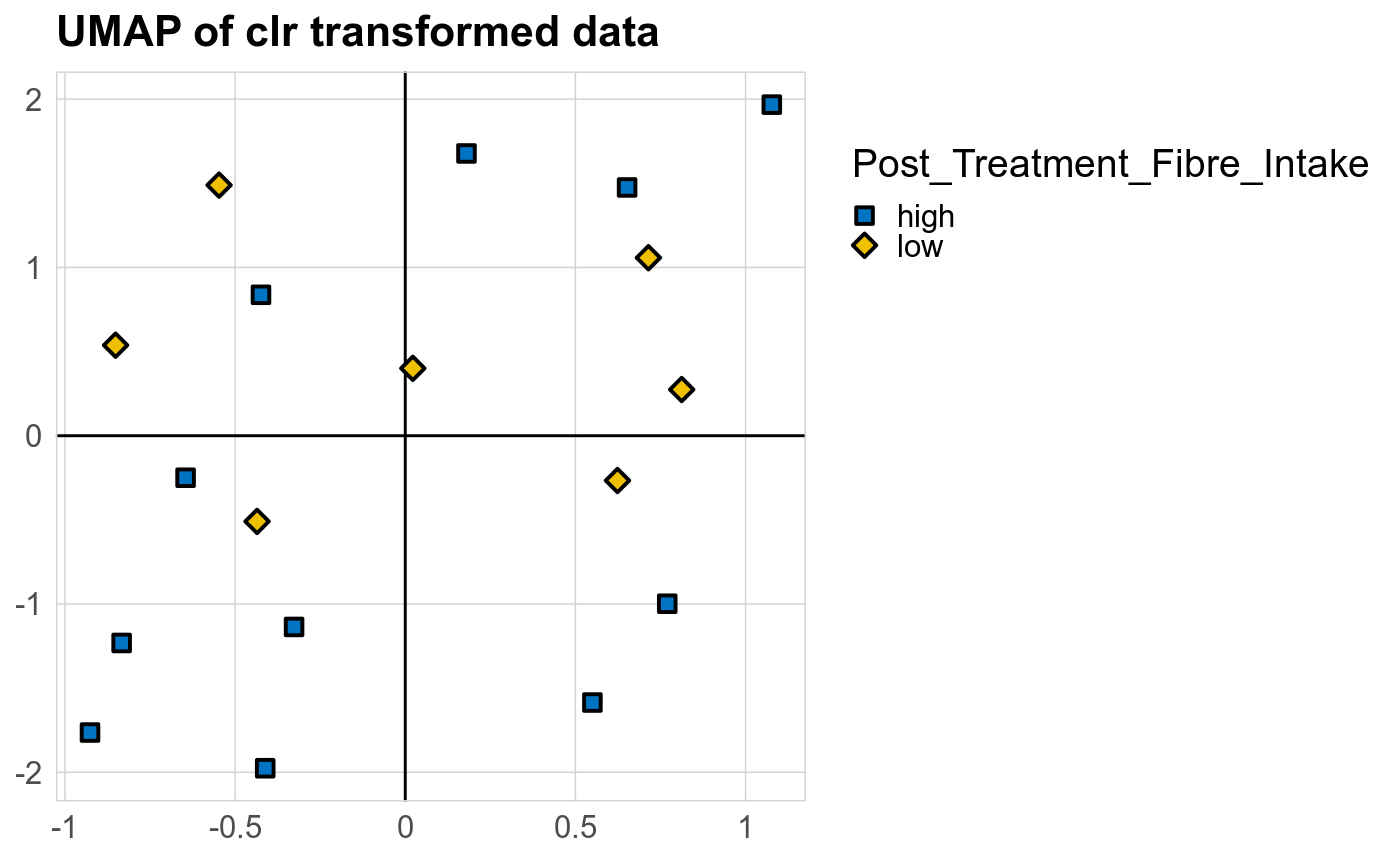
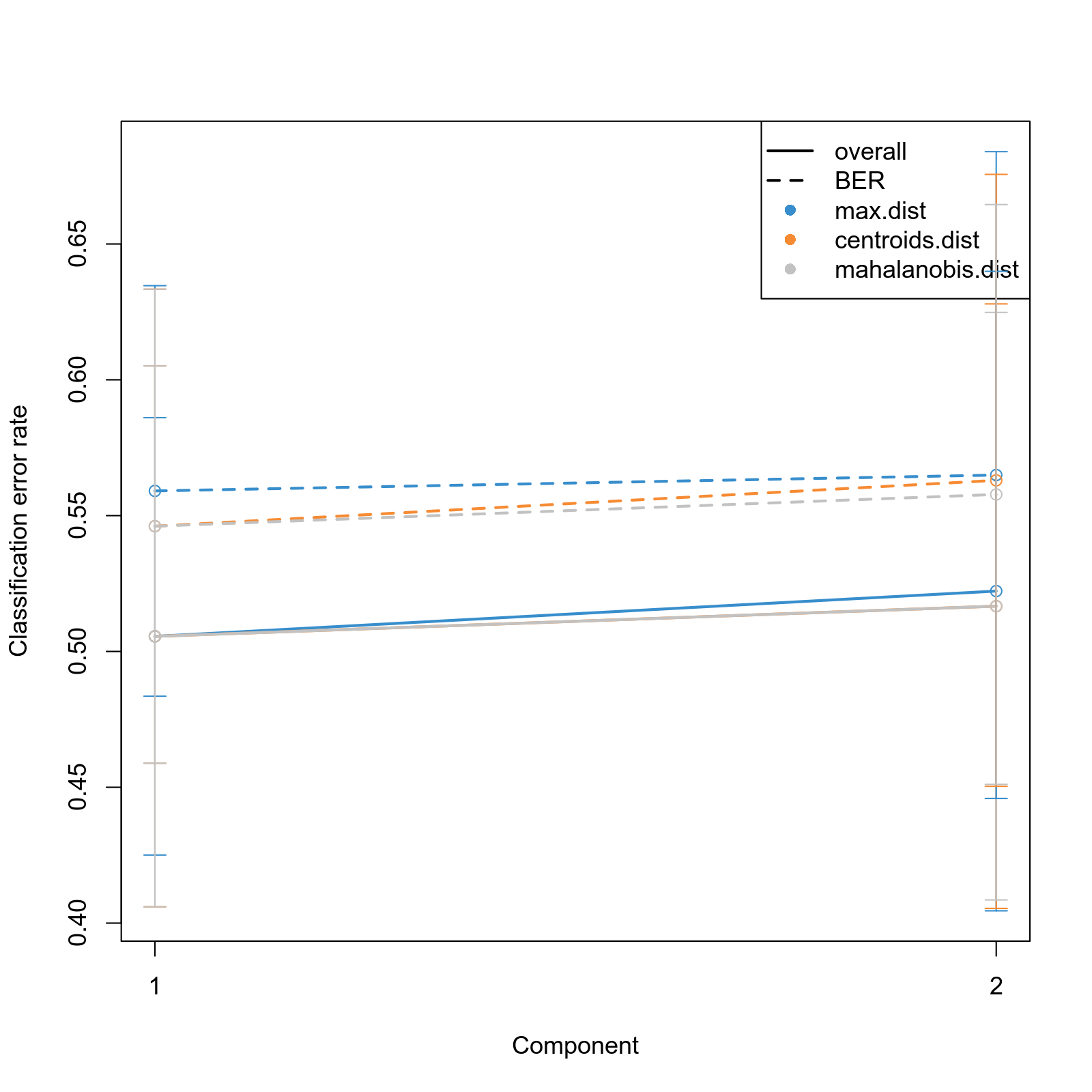
Taxonomic profiles were analyzed using supervised and unsupervised multivariate methods. Profiles were ordinated using the unsupervised methods Principal Coordinates Analysis (PCoA), Non-Metric Multidimensional Scaling (NMDS) and Principal Component Analysis (PCA). PCoA and NMDS are related to PCA, but take dissimlarity matrices as input. PCoA and NMDS both attempt to represent the pairwise dissimlarities between samples in low dimensional space as close as possible. NMDS is a rank-based approach and therefore less effected by outliers.
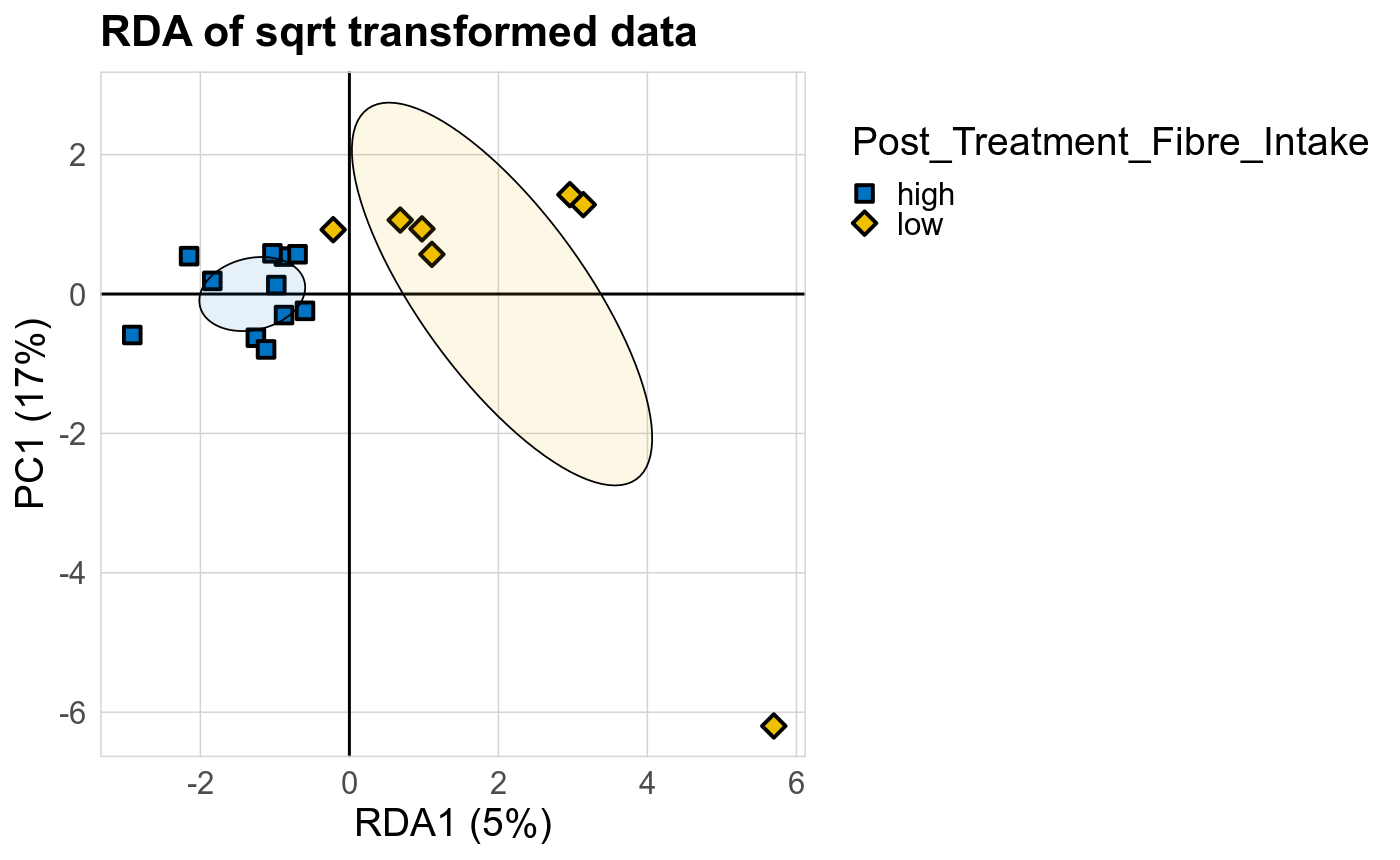
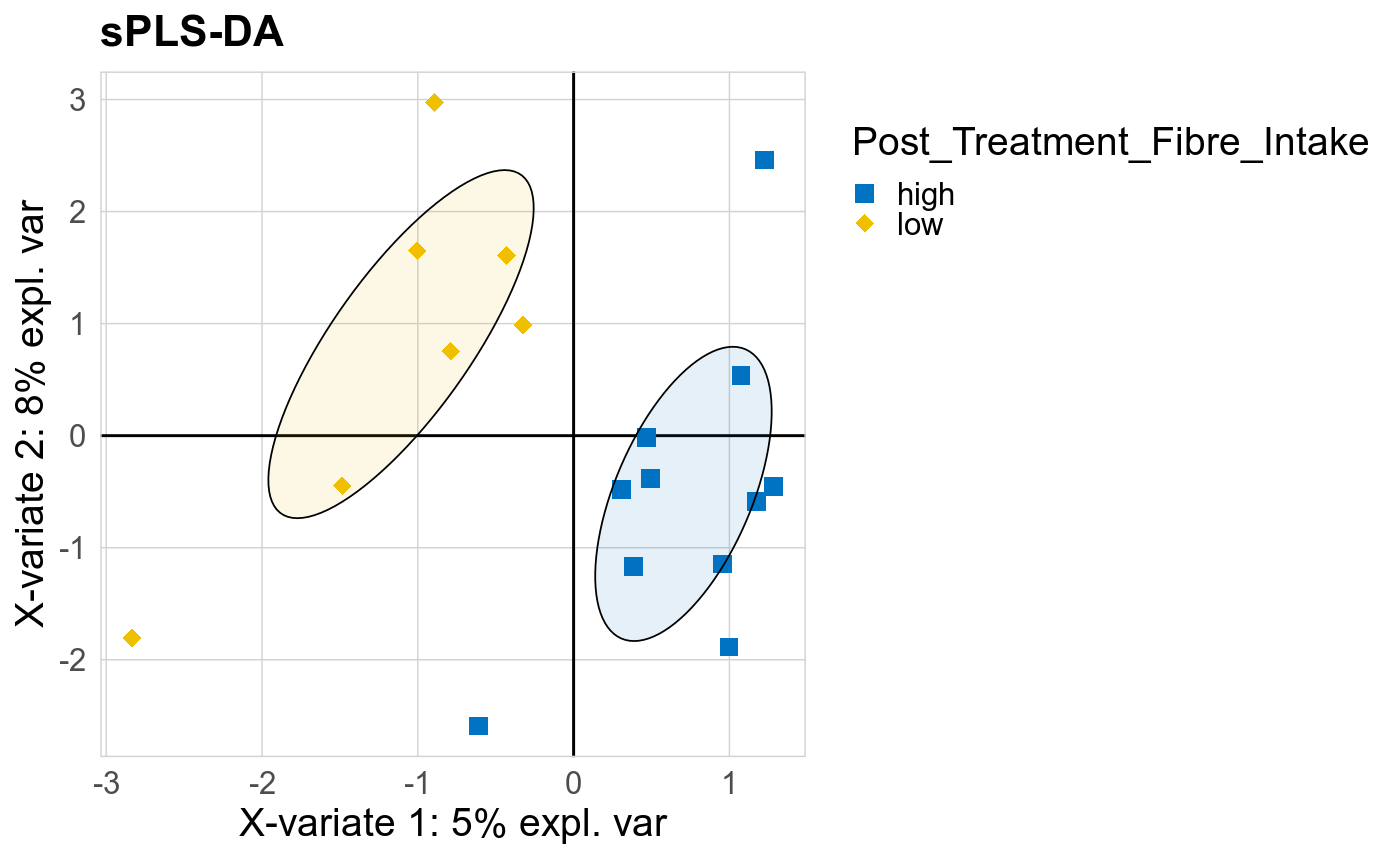
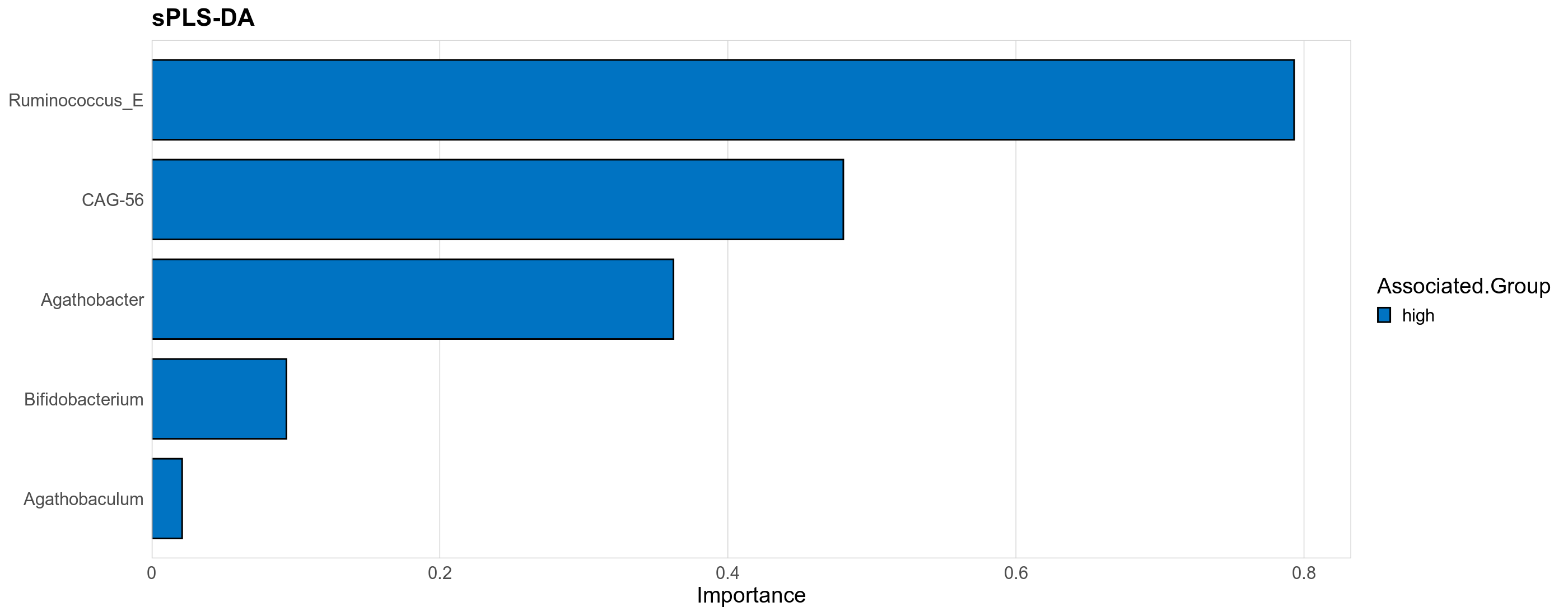
The supervised methods Adonis and Redundancy analysis (RDA) were used to assess if variance in microbial community composition can be attributed to the study condition. NMDS, PCoA and Adonis were run on Bray-Curtis dissimilarities. A short introduction of the used methods can be found at the GUide to STatistical Analysis in Microbial Ecology (GUSTA ME). Sparse Partial Least Square Discriminant Analysis (sPLS-DA) from the MixMc package was additionaly used to extract features associated with the study condition.
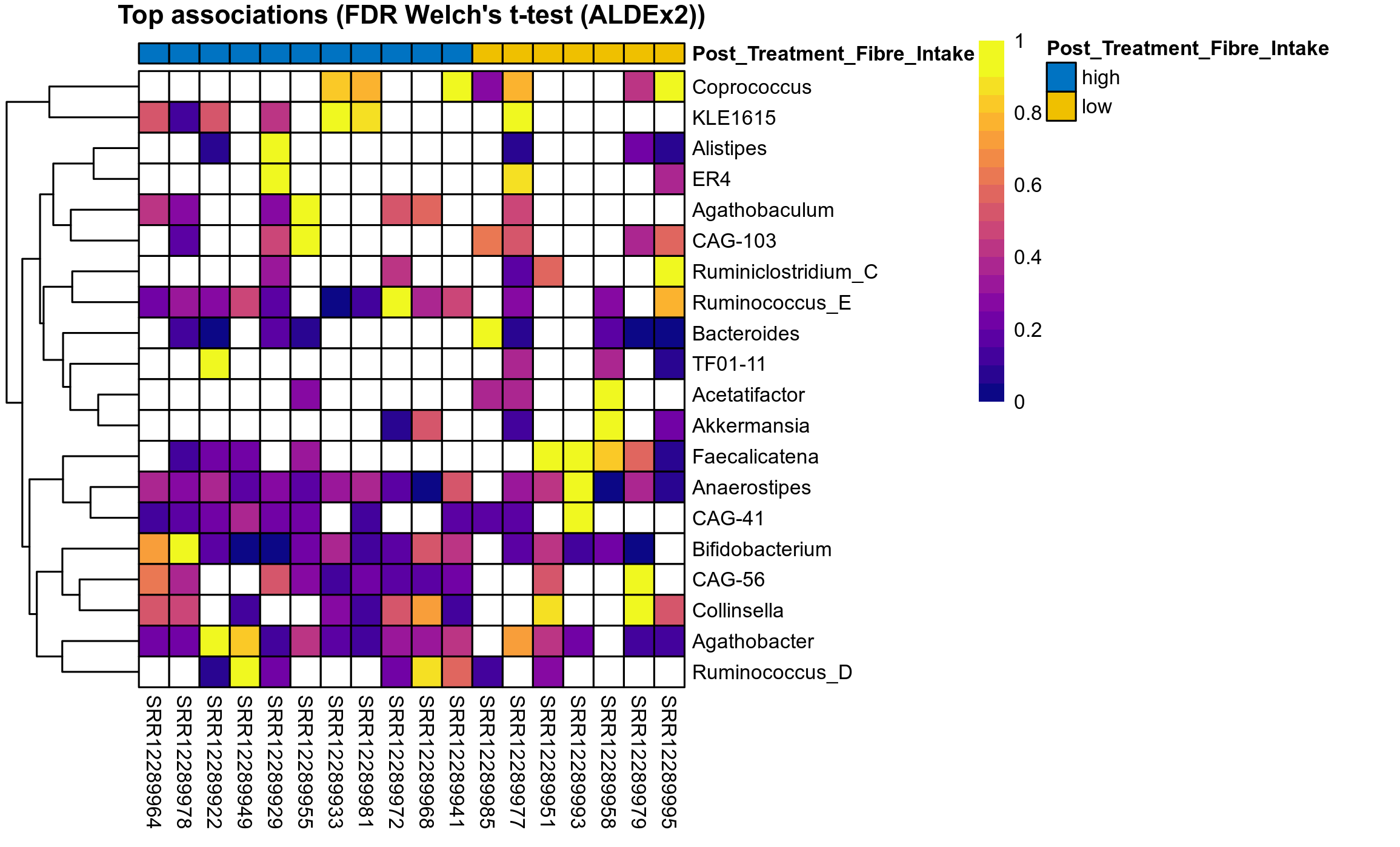
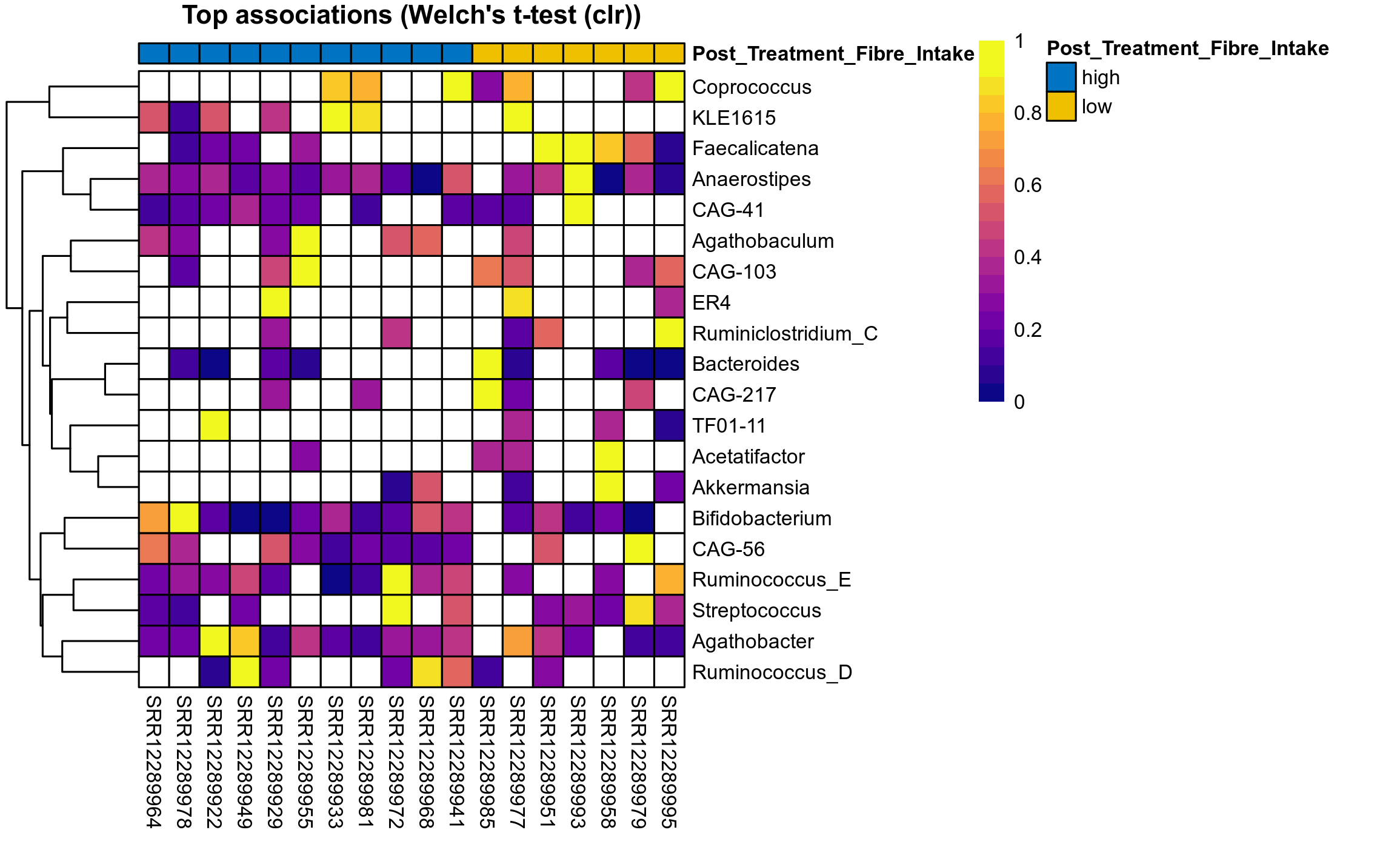
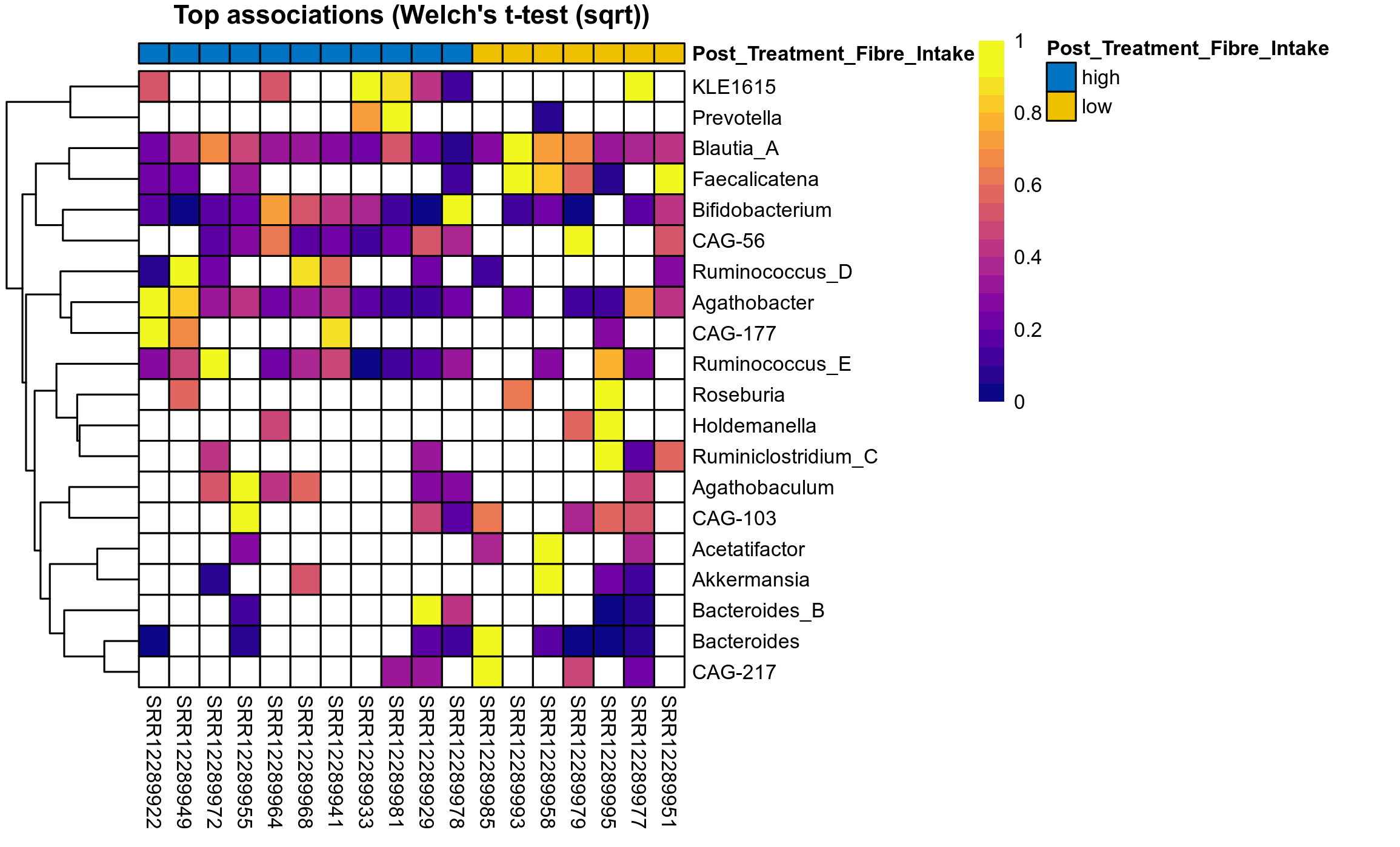
Differentially abundant genera were identified by ANOVA or LMER (linear mixed effect regression) of clr transformed relative abudances, Fisher's exact test and/or ALDEx2 (on genera read counts). Fisher's exact test is used to test for differences in the detection rate, i.e. number of samples in which each genus has been detected.
LMER is used for repeated measures data, using random effects to control for correlation between samples from the same subject. Fixed effects are included for treatment groups, time, and treatment over time, where appropriate. The LMER P values correspond to a nested model test of the significance of including the corresponding fixed effect.
ALDEx2 uses subsampling (Bayesian sampling) to estimate the underlying technical variation. For each subsample instance, center log-ratio transformed data is statistically compared across study groups and computed P values are corrected for multiple testing using the Benjamini–Hochberg procedure. The expected P value (mean P value) is reported, which are those that would likely have been observed if the same samples had been run multiple times. The expected values are reported for both the distribution of P values and for the distribution of Benjamini–Hochberg corrected values.
| Taxon | GTDB taxonomy | P Welch's t-test (sqrt) | FDR Welch's t-test (sqrt) | Pbonf Welch's t-test (sqrt) | Cohen's d Welch's t-test (sqrt) | P Welch's t-test (clr) | FDR Welch's t-test (clr) | Pbonf Welch's t-test (clr) | Cohen's d Welch's t-test (clr) | P Fisher's exact test | FDR Fisher's exact test | Pbonf Fisher's exact test | P Welch's t-test (ALDEx2) | FDR Welch's t-test (ALDEx2) | P Wilcoxon rank test (ALDEx2) | FDR Wilcoxon rank test (ALDEx2) | Mean Pos | Mean Abundance | Median Abundance | Mean Post_Treatment_Fibre_Intakehigh | Median Post_Treatment_Fibre_Intakehigh | SD Post_Treatment_Fibre_Intakehigh | Mean Post_Treatment_Fibre_Intakelow | Median Post_Treatment_Fibre_Intakelow | SD Post_Treatment_Fibre_Intakelow | Fold Change Log2(Post_Treatment_Fibre_Intakelow/Post_Treatment_Fibre_Intakehigh) | Positive samples | Positive Post_Treatment_Fibre_Intakehigh | Positive Post_Treatment_Fibre_Intakelow | Positive_Post_Treatment_Fibre_Intakehigh_percent | Positive_Post_Treatment_Fibre_Intakelow_percent |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
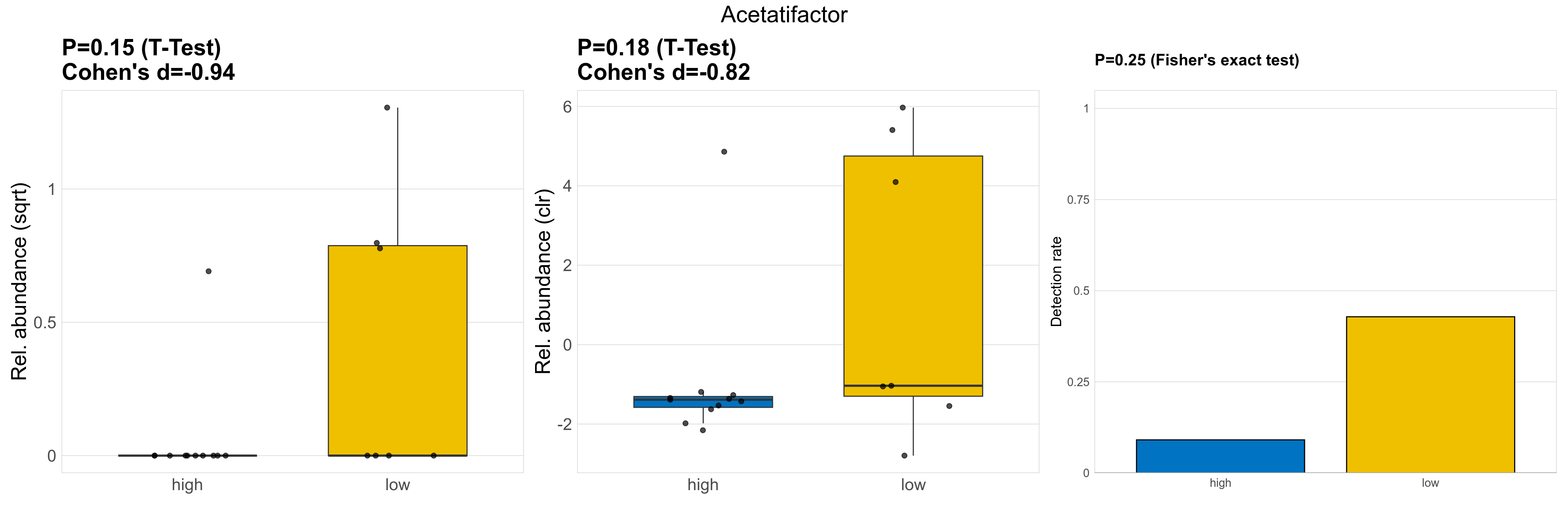
| Acetatifactor | Acetatifactor | 0.15 | 0.93 | 1 | -0.94 | 0.18 | 0.85 | 1 | -0.82 | 0.25 | 1 | 1 | 0.2 | 0.81 | 0.27 | 0.83 | 0.86 | 0.19 | 0 | 0.043 | 0 | 0.14 | 0.42 | 0 | 0.64 | 3.3 | 4 / 18 (22%) | 1 / 11 (9.1%) | 3 / 7 (43%) | 0.0909 | 0.429 |
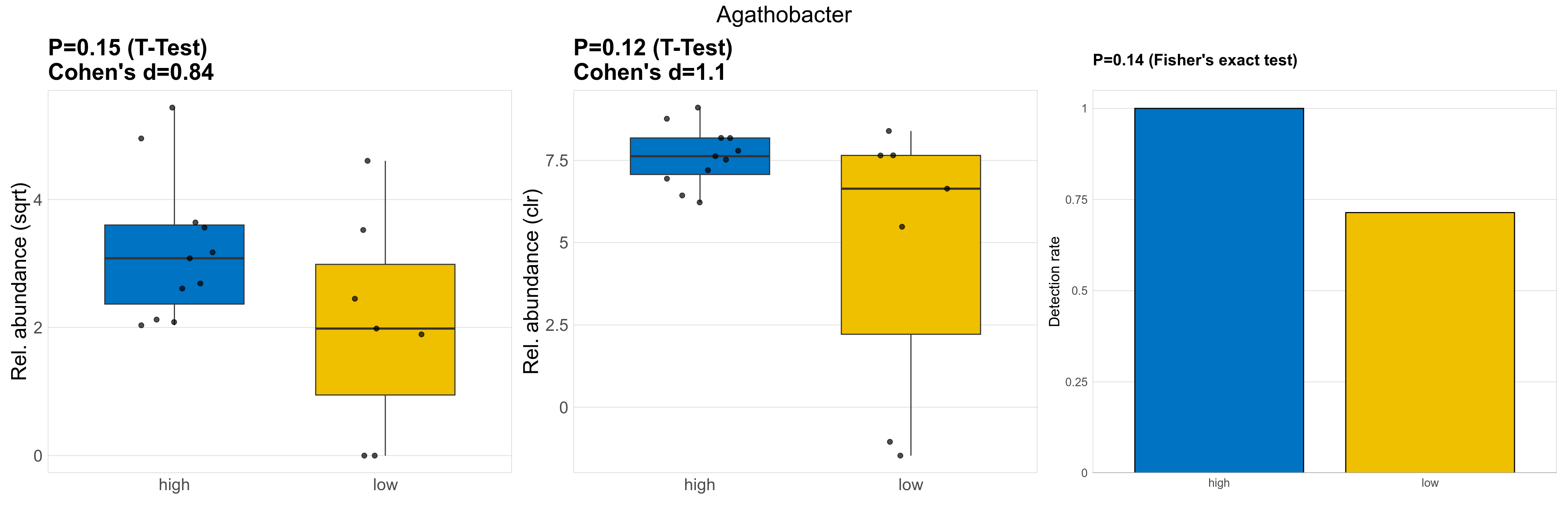
| Agathobacter | Agathobacter | 0.15 | 0.93 | 1 | 0.84 | 0.12 | 0.85 | 1 | 1.1 | 0.14 | 1 | 1 | 0.12 | 0.8 | 0.13 | 0.8 | 11 | 9.7 | 7 | 12 | 9.5 | 8.4 | 6.7 | 3.9 | 7.6 | -0.84 | 16 / 18 (89%) | 11 / 11 (100%) | 5 / 7 (71%) | 1 | 0.714 |
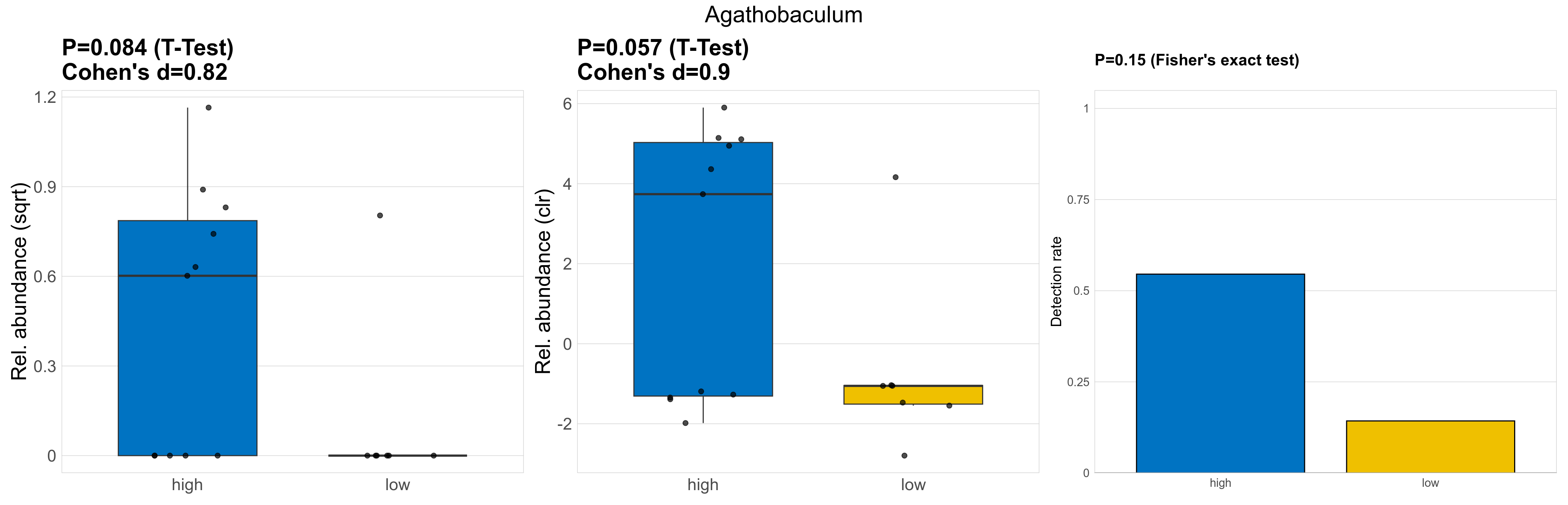
| Agathobaculum | Agathobaculum | 0.084 | 0.93 | 1 | 0.82 | 0.057 | 0.85 | 1 | 0.9 | 0.15 | 1 | 1 | 0.094 | 0.8 | 0.16 | 0.8 | 0.69 | 0.27 | 0 | 0.38 | 0.36 | 0.44 | 0.092 | 0 | 0.24 | -2 | 7 / 18 (39%) | 6 / 11 (55%) | 1 / 7 (14%) | 0.545 | 0.143 |
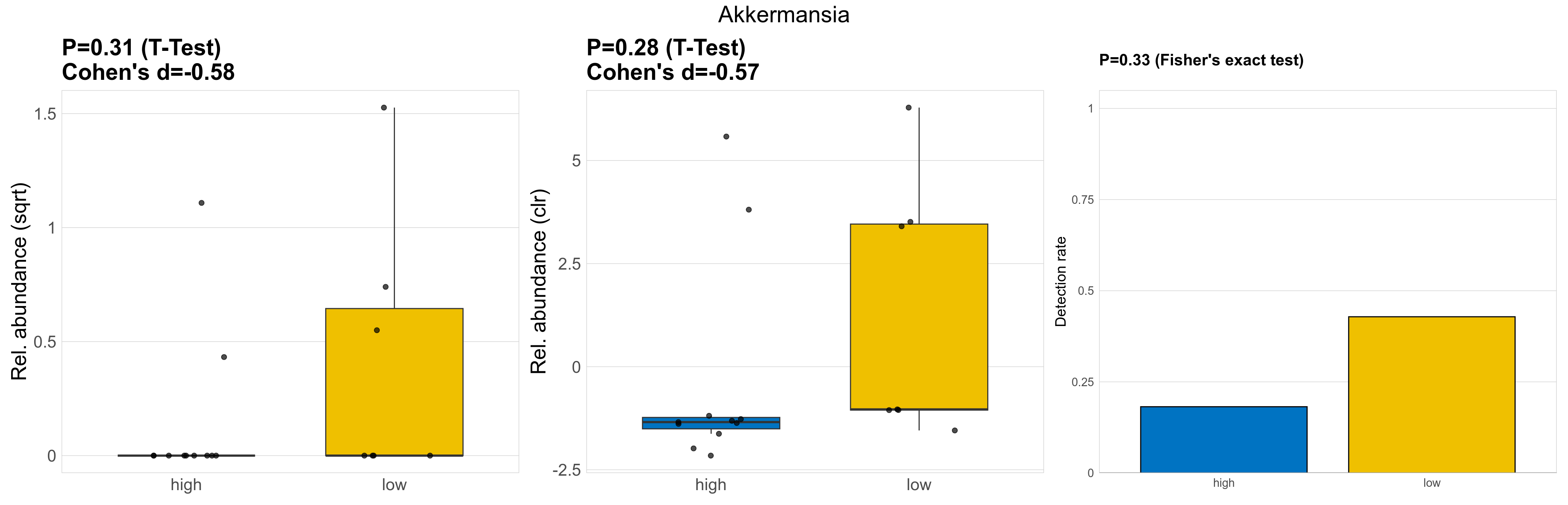
| Akkermansia | Akkermansia | 0.31 | 0.93 | 1 | -0.58 | 0.28 | 0.85 | 1 | -0.57 | 0.33 | 1 | 1 | 0.27 | 0.82 | 0.3 | 0.84 | 0.92 | 0.26 | 0 | 0.13 | 0 | 0.37 | 0.45 | 0 | 0.85 | 1.8 | 5 / 18 (28%) | 2 / 11 (18%) | 3 / 7 (43%) | 0.182 | 0.429 |
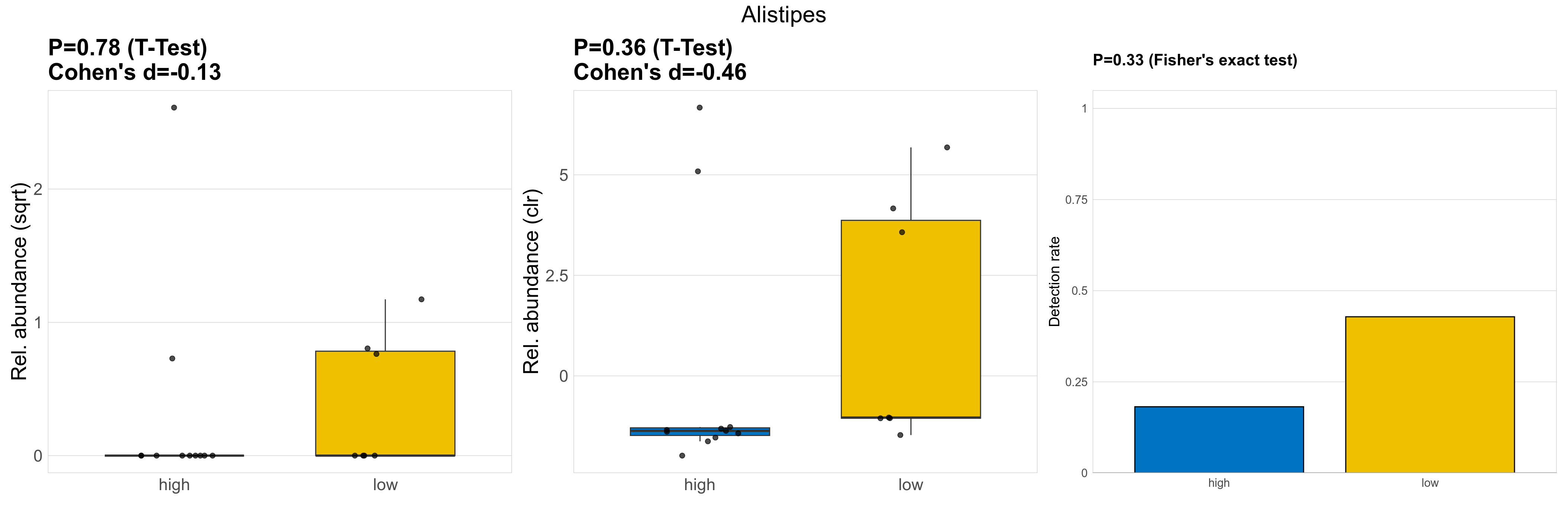
| Alistipes | Alistipes | 0.78 | 0.95 | 1 | -0.13 | 0.36 | 0.85 | 1 | -0.46 | 0.33 | 1 | 1 | 0.29 | 0.83 | 0.33 | 0.85 | 2 | 0.55 | 0 | 0.67 | 0 | 2 | 0.37 | 0 | 0.53 | -0.86 | 5 / 18 (28%) | 2 / 11 (18%) | 3 / 7 (43%) | 0.182 | 0.429 |
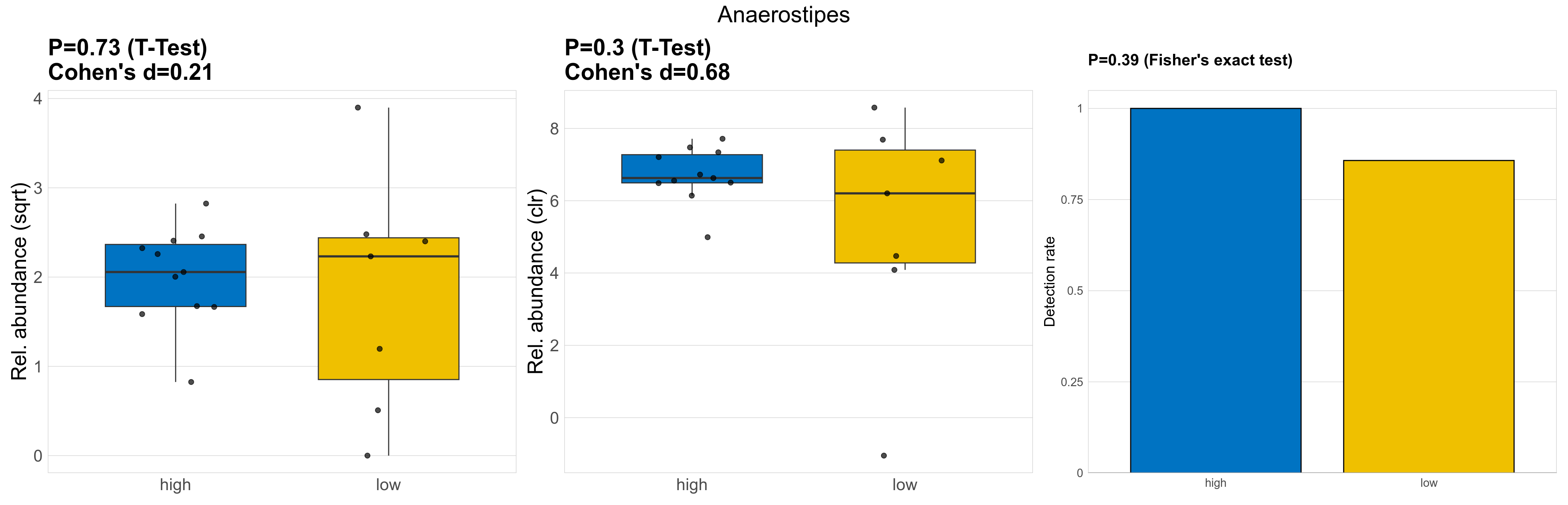
| Anaerostipes | Anaerostipes | 0.73 | 0.95 | 1 | 0.21 | 0.3 | 0.85 | 1 | 0.68 | 0.39 | 1 | 1 | 0.29 | 0.83 | 0.41 | 0.87 | 4.8 | 4.5 | 4.6 | 4.3 | 4.2 | 2 | 4.8 | 5 | 5.3 | 0.16 | 17 / 18 (94%) | 11 / 11 (100%) | 6 / 7 (86%) | 1 | 0.857 |
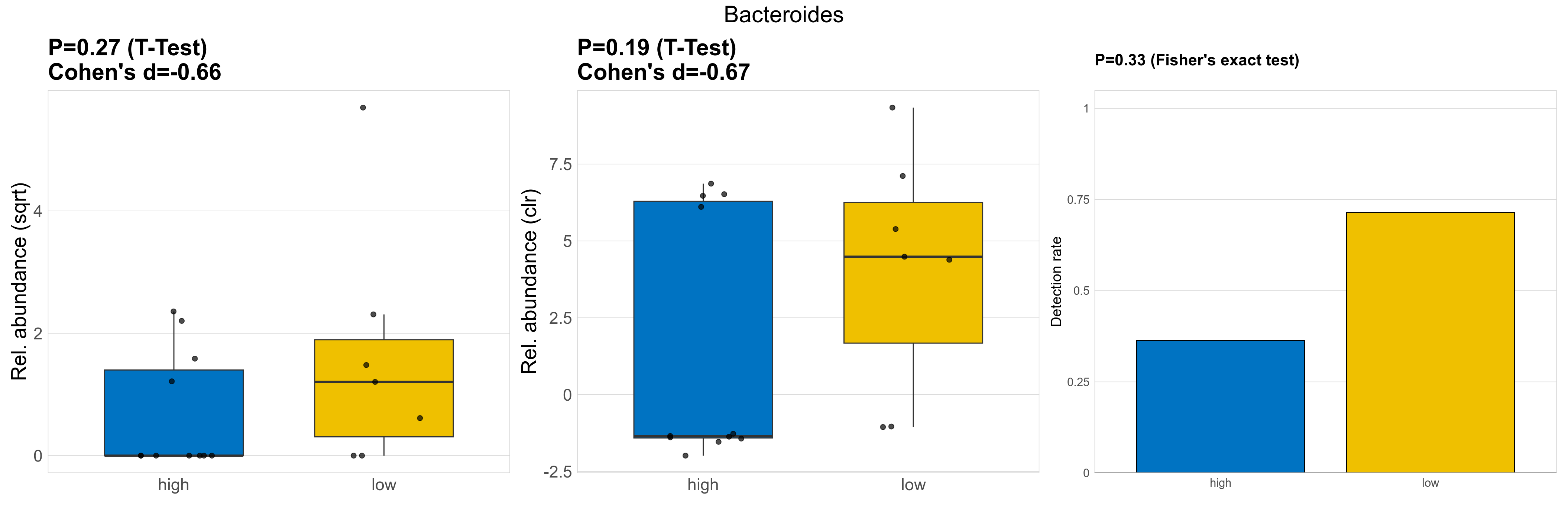
| Bacteroides | Bacteroides | 0.27 | 0.93 | 1 | -0.66 | 0.19 | 0.85 | 1 | -0.67 | 0.33 | 1 | 1 | 0.17 | 0.8 | 0.25 | 0.83 | 6.2 | 3.1 | 0.19 | 1.3 | 0 | 2.1 | 6 | 1.5 | 12 | 2.2 | 9 / 18 (50%) | 4 / 11 (36%) | 5 / 7 (71%) | 0.364 | 0.714 |
| Bacteroides_B | Bacteroides_B | 0.3 | 0.93 | 1 | 0.43 | 0.68 | 0.94 | 1 | 0.19 | 1 | 1 | 1 | 0.79 | 0.94 | 0.66 | 0.92 | 7 | 2 | 0 | 3 | 0 | 6.7 | 0.33 | 0 | 0.79 | -3.2 | 5 / 18 (28%) | 3 / 11 (27%) | 2 / 7 (29%) | 0.273 | 0.286 |
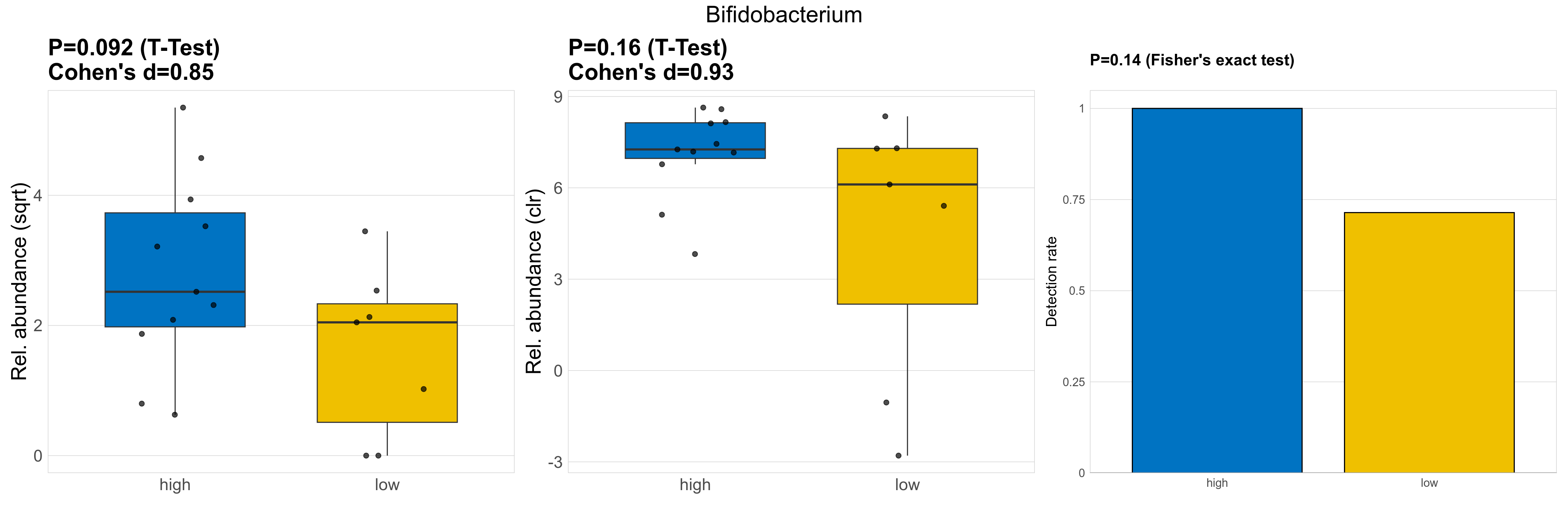
| Bifidobacterium | Bifidobacterium | 0.092 | 0.93 | 1 | 0.85 | 0.16 | 0.85 | 1 | 0.93 | 0.14 | 1 | 1 | 0.19 | 0.81 | 0.32 | 0.85 | 8.5 | 7.6 | 4.9 | 9.8 | 6.3 | 8.9 | 4 | 4.2 | 4.3 | -1.3 | 16 / 18 (89%) | 11 / 11 (100%) | 5 / 7 (71%) | 1 | 0.714 |
| Blautia | Blautia | 0.37 | 0.95 | 1 | -0.56 | 0.41 | 0.87 | 1 | -0.47 | 0.53 | 1 | 1 | 0.46 | 0.87 | 0.54 | 0.89 | 2.3 | 0.38 | 0 | 0.1 | 0 | 0.33 | 0.82 | 0 | 2 | 3 | 3 / 18 (17%) | 1 / 11 (9.1%) | 2 / 7 (29%) | 0.0909 | 0.286 |
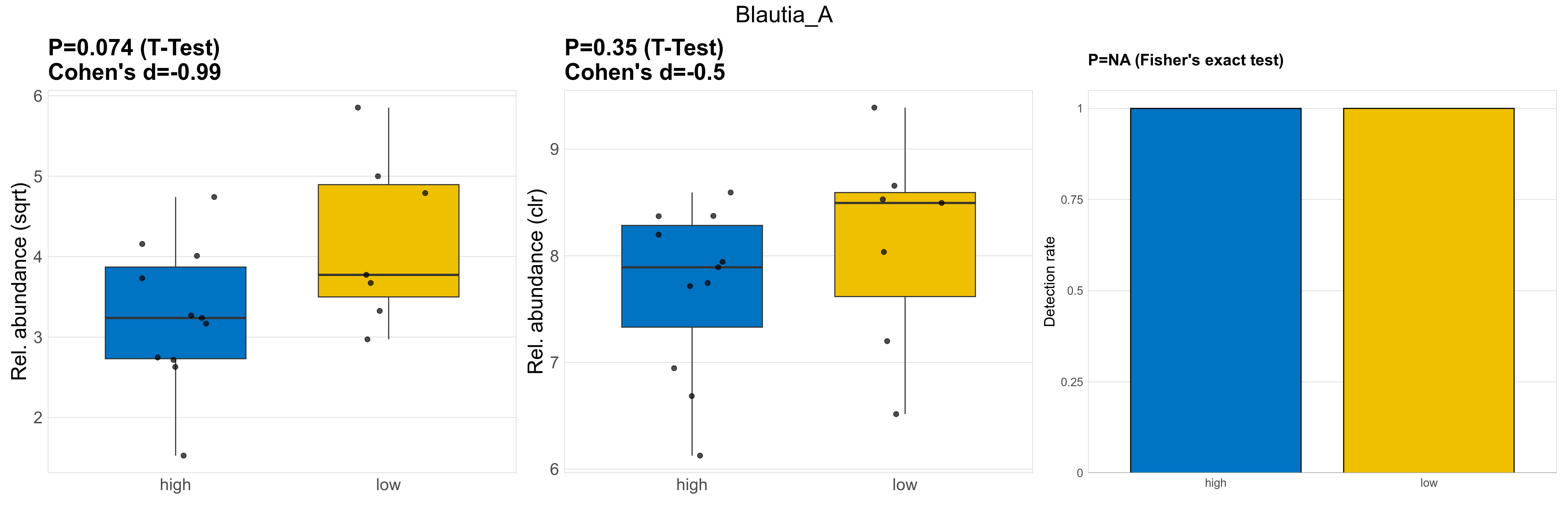
| Blautia_A | Blautia_A | 0.074 | 0.93 | 1 | -0.99 | 0.35 | 0.85 | 1 | -0.5 | NA | NA | NA | 0.62 | 0.9 | 0.4 | 0.87 | 14 | 14 | 12 | 11 | 10 | 5.7 | 19 | 14 | 9.2 | 0.79 | 18 / 18 (100%) | 11 / 11 (100%) | 7 / 7 (100%) | 1 | 1 |
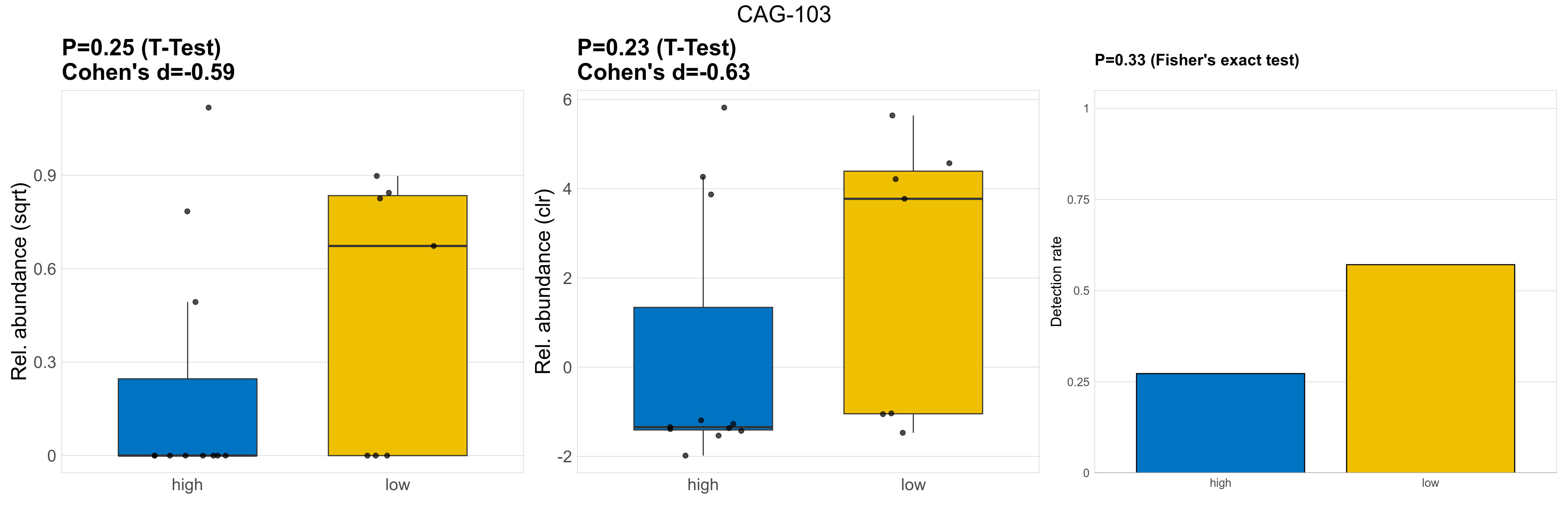
| CAG-103 | CAG-103 | 0.25 | 0.93 | 1 | -0.59 | 0.23 | 0.85 | 1 | -0.63 | 0.33 | 1 | 1 | 0.22 | 0.81 | 0.25 | 0.83 | 0.68 | 0.26 | 0 | 0.19 | 0 | 0.4 | 0.38 | 0.45 | 0.37 | 1 | 7 / 18 (39%) | 3 / 11 (27%) | 4 / 7 (57%) | 0.273 | 0.571 |
| CAG-110 | CAG-110 | 0.64 | 0.95 | 1 | -0.28 | 0.97 | 0.97 | 1 | 0.021 | 1 | 1 | 1 | 0.72 | 0.92 | 0.63 | 0.91 | 0.92 | 0.15 | 0 | 0.057 | 0 | 0.13 | 0.31 | 0 | 0.81 | 2.4 | 3 / 18 (17%) | 2 / 11 (18%) | 1 / 7 (14%) | 0.182 | 0.143 |
| CAG-1427 | CAG-1427 | 0.65 | 0.95 | 1 | -0.25 | 0.7 | 0.94 | 1 | -0.2 | 1 | 1 | 1 | 0.65 | 0.91 | 0.55 | 0.9 | 0.47 | 0.11 | 0 | 0.074 | 0 | 0.17 | 0.15 | 0 | 0.35 | 1 | 4 / 18 (22%) | 2 / 11 (18%) | 2 / 7 (29%) | 0.182 | 0.286 |
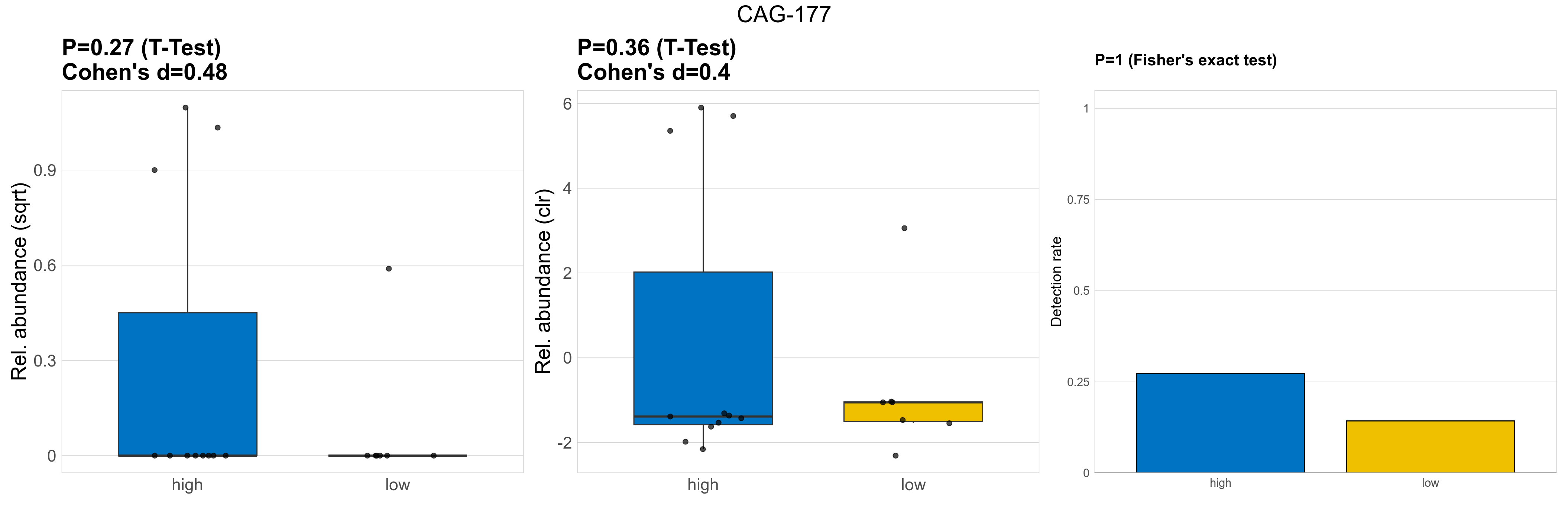
| CAG-177 | CAG-177 | 0.27 | 0.93 | 1 | 0.48 | 0.36 | 0.85 | 1 | 0.4 | 1 | 1 | 1 | 0.56 | 0.89 | 0.69 | 0.93 | 0.86 | 0.19 | 0 | 0.28 | 0 | 0.49 | 0.05 | 0 | 0.13 | -2.5 | 4 / 18 (22%) | 3 / 11 (27%) | 1 / 7 (14%) | 0.273 | 0.143 |
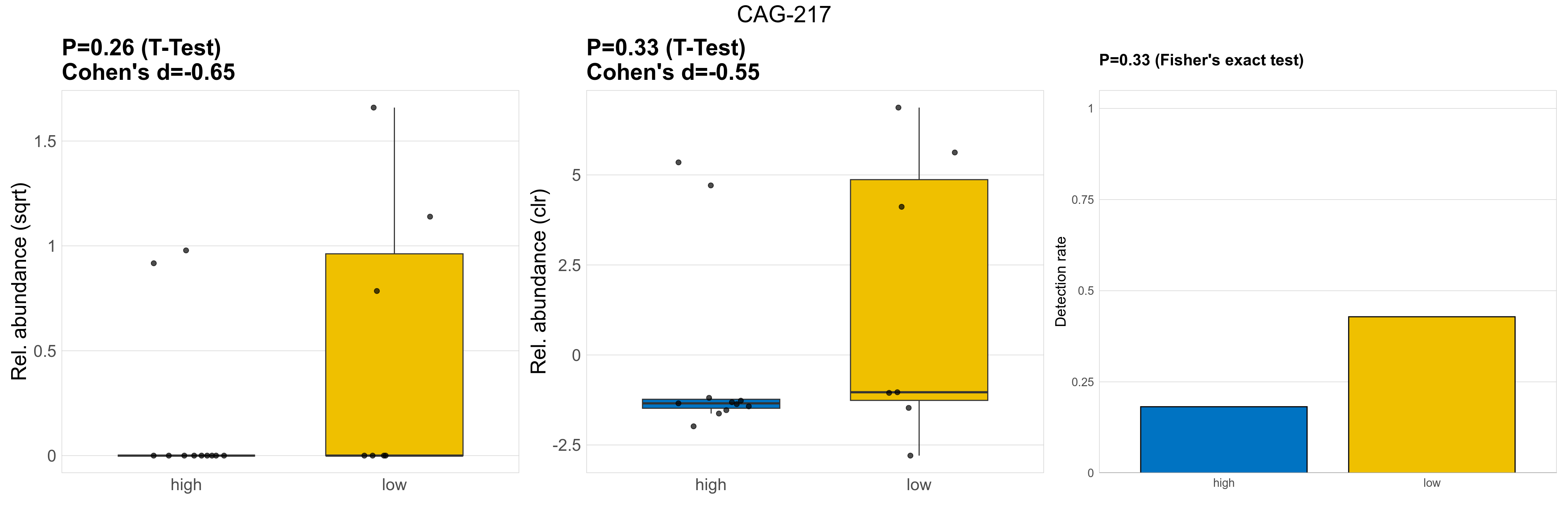
| CAG-217 | CAG-217 | 0.26 | 0.93 | 1 | -0.65 | 0.33 | 0.85 | 1 | -0.55 | 0.33 | 1 | 1 | 0.36 | 0.84 | 0.38 | 0.85 | 1.3 | 0.36 | 0 | 0.16 | 0 | 0.36 | 0.67 | 0 | 1 | 2.1 | 5 / 18 (28%) | 2 / 11 (18%) | 3 / 7 (43%) | 0.182 | 0.429 |
| CAG-274 | CAG-274 | 0.7 | 0.95 | 1 | 0.2 | 0.41 | 0.87 | 1 | 0.41 | 0.6 | 1 | 1 | 0.39 | 0.84 | 0.47 | 0.87 | 0.62 | 0.17 | 0 | 0.17 | 0 | 0.3 | 0.17 | 0 | 0.46 | 0 | 5 / 18 (28%) | 4 / 11 (36%) | 1 / 7 (14%) | 0.364 | 0.143 |
| CAG-302 | CAG-302 | 0.63 | 0.95 | 1 | 0.22 | 0.7 | 0.94 | 1 | 0.18 | 1 | 1 | 1 | 0.75 | 0.93 | 0.62 | 0.91 | 0.62 | 0.1 | 0 | 0.13 | 0 | 0.3 | 0.054 | 0 | 0.14 | -1.3 | 3 / 18 (17%) | 2 / 11 (18%) | 1 / 7 (14%) | 0.182 | 0.143 |
| CAG-41 | CAG-41 | 0.73 | 0.95 | 1 | 0.2 | 0.33 | 0.85 | 1 | 0.52 | 0.33 | 1 | 1 | 0.32 | 0.83 | 0.47 | 0.88 | 0.81 | 0.5 | 0.42 | 0.44 | 0.48 | 0.35 | 0.58 | 0 | 1.1 | 0.4 | 11 / 18 (61%) | 8 / 11 (73%) | 3 / 7 (43%) | 0.727 | 0.429 |
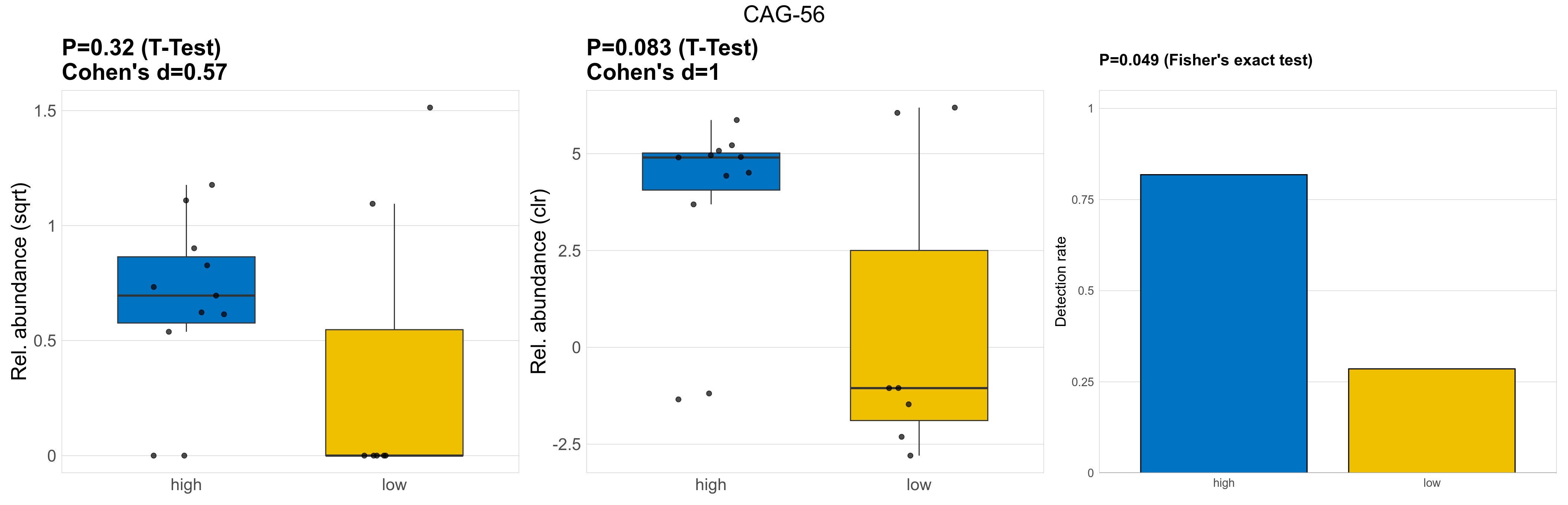
| CAG-56 | CAG-56 | 0.32 | 0.93 | 1 | 0.57 | 0.083 | 0.85 | 1 | 1 | 0.049 | 1 | 1 | 0.071 | 0.8 | 0.22 | 0.83 | 0.88 | 0.54 | 0.38 | 0.56 | 0.48 | 0.44 | 0.5 | 0 | 0.91 | -0.16 | 11 / 18 (61%) | 9 / 11 (82%) | 2 / 7 (29%) | 0.818 | 0.286 |
| CAG-83 | CAG-83 | 0.88 | 0.95 | 1 | -0.084 | 0.84 | 0.94 | 1 | 0.097 | 1 | 1 | 1 | 0.73 | 0.92 | 0.63 | 0.92 | 1.3 | 0.22 | 0 | 0.17 | 0 | 0.37 | 0.32 | 0 | 0.83 | 0.91 | 3 / 18 (17%) | 2 / 11 (18%) | 1 / 7 (14%) | 0.182 | 0.143 |
| Clostridium | Clostridium | 0.86 | 0.95 | 1 | 0.083 | 0.88 | 0.94 | 1 | 0.07 | 1 | 1 | 1 | 0.75 | 0.93 | 0.68 | 0.93 | 0.31 | 0.087 | 0 | 0.095 | 0 | 0.18 | 0.074 | 0 | 0.16 | -0.36 | 5 / 18 (28%) | 3 / 11 (27%) | 2 / 7 (29%) | 0.273 | 0.286 |
| Collinsella | Collinsella | 0.87 | 0.95 | 1 | 0.089 | 0.37 | 0.85 | 1 | 0.48 | 0.33 | 1 | 1 | 0.33 | 0.83 | 0.47 | 0.88 | 1.5 | 0.93 | 0.43 | 0.83 | 0.44 | 0.81 | 1.1 | 0 | 1.4 | 0.41 | 11 / 18 (61%) | 8 / 11 (73%) | 3 / 7 (43%) | 0.727 | 0.429 |
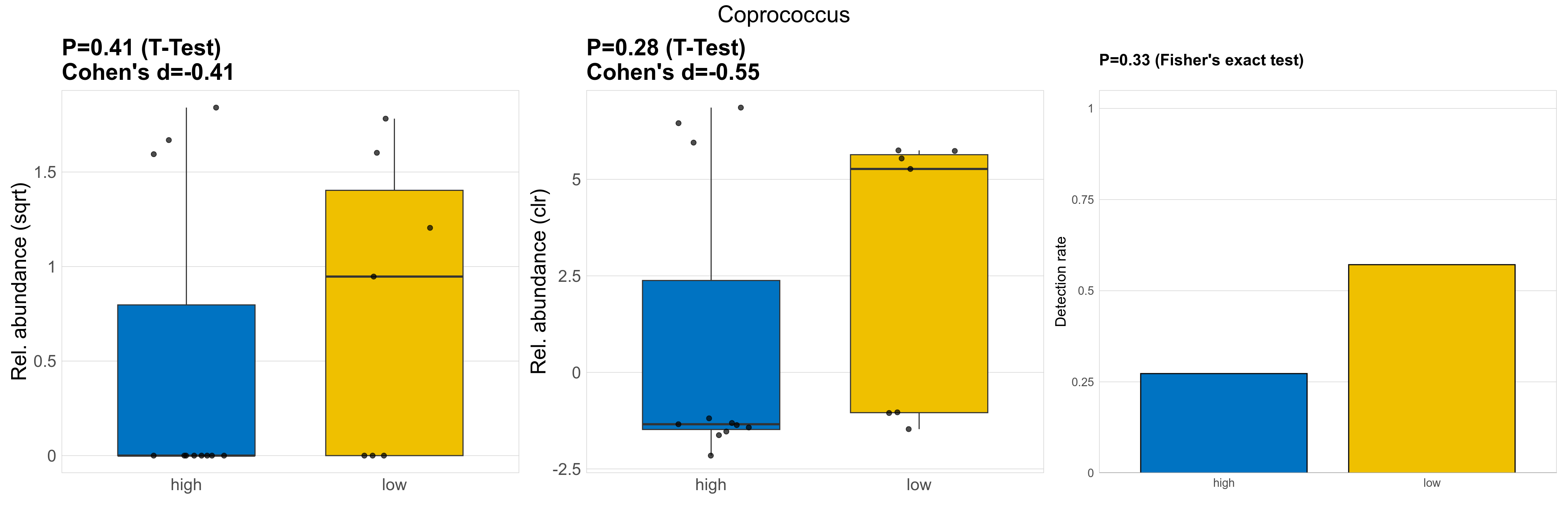
| Coprococcus | Coprococcus | 0.41 | 0.95 | 1 | -0.41 | 0.28 | 0.85 | 1 | -0.55 | 0.33 | 1 | 1 | 0.24 | 0.82 | 0.4 | 0.87 | 2.4 | 0.93 | 0 | 0.79 | 0 | 1.4 | 1.2 | 0.9 | 1.3 | 0.6 | 7 / 18 (39%) | 3 / 11 (27%) | 4 / 7 (57%) | 0.273 | 0.571 |
| Coprococcus_A | Coprococcus_A | 0.71 | 0.95 | 1 | -0.19 | 0.66 | 0.94 | 1 | -0.22 | 1 | 1 | 1 | 0.58 | 0.89 | 0.5 | 0.89 | 0.47 | 0.1 | 0 | 0.091 | 0 | 0.22 | 0.13 | 0 | 0.25 | 0.51 | 4 / 18 (22%) | 2 / 11 (18%) | 2 / 7 (29%) | 0.182 | 0.286 |
| Coprococcus_B | Coprococcus_B | 0.82 | 0.95 | 1 | 0.12 | 0.59 | 0.94 | 1 | 0.28 | 0.63 | 1 | 1 | 0.59 | 0.9 | 0.85 | 0.96 | 0.68 | 0.46 | 0.5 | 0.45 | 0.48 | 0.36 | 0.47 | 0.56 | 0.55 | 0.063 | 12 / 18 (67%) | 8 / 11 (73%) | 4 / 7 (57%) | 0.727 | 0.571 |
| Dialister | Dialister | 0.83 | 0.95 | 1 | -0.11 | 0.86 | 0.94 | 1 | -0.088 | 1 | 1 | 1 | 0.85 | 0.95 | 0.78 | 0.95 | 1.3 | 0.51 | 0 | 0.48 | 0 | 0.83 | 0.57 | 0 | 1 | 0.25 | 7 / 18 (39%) | 4 / 11 (36%) | 3 / 7 (43%) | 0.364 | 0.429 |
| Dorea | Dorea | 0.87 | 0.95 | 1 | -0.094 | 0.45 | 0.91 | 1 | 0.49 | 0.39 | 1 | 1 | 0.38 | 0.85 | 0.88 | 0.97 | 1.3 | 1.2 | 1.1 | 1.1 | 1 | 0.75 | 1.5 | 1.4 | 1.3 | 0.45 | 17 / 18 (94%) | 11 / 11 (100%) | 6 / 7 (86%) | 1 | 0.857 |
| ER4 | ER4 | 0.47 | 0.95 | 1 | -0.39 | 0.34 | 0.85 | 1 | -0.51 | 0.53 | 1 | 1 | 0.34 | 0.84 | 0.34 | 0.83 | 0.36 | 0.06 | 0 | 0.044 | 0 | 0.14 | 0.086 | 0 | 0.16 | 0.97 | 3 / 18 (17%) | 1 / 11 (9.1%) | 2 / 7 (29%) | 0.0909 | 0.286 |
| Erysipelatoclostridium | Erysipelatoclostridium | 0.83 | 0.95 | 1 | -0.12 | 0.94 | 0.97 | 1 | 0.037 | 1 | 1 | 1 | 0.85 | 0.95 | 0.83 | 0.96 | 0.82 | 0.59 | 0.39 | 0.51 | 0.46 | 0.47 | 0.72 | 0.25 | 0.99 | 0.5 | 13 / 18 (72%) | 8 / 11 (73%) | 5 / 7 (71%) | 0.727 | 0.714 |
| Eubacterium_E | Eubacterium_E | 0.72 | 0.95 | 1 | 0.18 | 0.7 | 0.94 | 1 | 0.2 | 1 | 1 | 1 | 0.7 | 0.92 | 0.9 | 0.97 | 2.2 | 1.9 | 1.8 | 2 | 2.1 | 1.2 | 1.8 | 1.7 | 1.2 | -0.15 | 16 / 18 (89%) | 10 / 11 (91%) | 6 / 7 (86%) | 0.909 | 0.857 |
| Eubacterium_F | Eubacterium_F | 0.67 | 0.95 | 1 | -0.25 | 0.96 | 0.97 | 1 | 0.03 | 1 | 1 | 1 | 0.79 | 0.93 | 0.67 | 0.92 | 1.4 | 0.24 | 0 | 0.1 | 0 | 0.26 | 0.45 | 0 | 1.2 | 2.2 | 3 / 18 (17%) | 2 / 11 (18%) | 1 / 7 (14%) | 0.182 | 0.143 |
| Eubacterium_I | Eubacterium_I | 0.63 | 0.95 | 1 | -0.25 | 0.72 | 0.94 | 1 | -0.19 | 1 | 1 | 1 | 0.73 | 0.92 | 0.7 | 0.93 | 0.63 | 0.14 | 0 | 0.11 | 0 | 0.25 | 0.19 | 0 | 0.36 | 0.79 | 4 / 18 (22%) | 2 / 11 (18%) | 2 / 7 (29%) | 0.182 | 0.286 |
| Eubacterium_R | Eubacterium_R | 0.92 | 0.95 | 1 | -0.051 | 0.83 | 0.94 | 1 | 0.1 | 1 | 1 | 1 | 0.76 | 0.93 | 0.66 | 0.93 | 1.5 | 0.25 | 0 | 0.2 | 0 | 0.46 | 0.33 | 0 | 0.86 | 0.72 | 3 / 18 (17%) | 2 / 11 (18%) | 1 / 7 (14%) | 0.182 | 0.143 |
| Faecalibacterium | Faecalibacterium | 0.56 | 0.95 | 1 | 0.28 | 0.59 | 0.94 | 1 | 0.28 | NA | NA | NA | 0.65 | 0.92 | 0.86 | 0.97 | 6.5 | 6.5 | 5.7 | 7 | 6.3 | 4.8 | 5.6 | 5.2 | 3.8 | -0.32 | 18 / 18 (100%) | 11 / 11 (100%) | 7 / 7 (100%) | 1 | 1 |
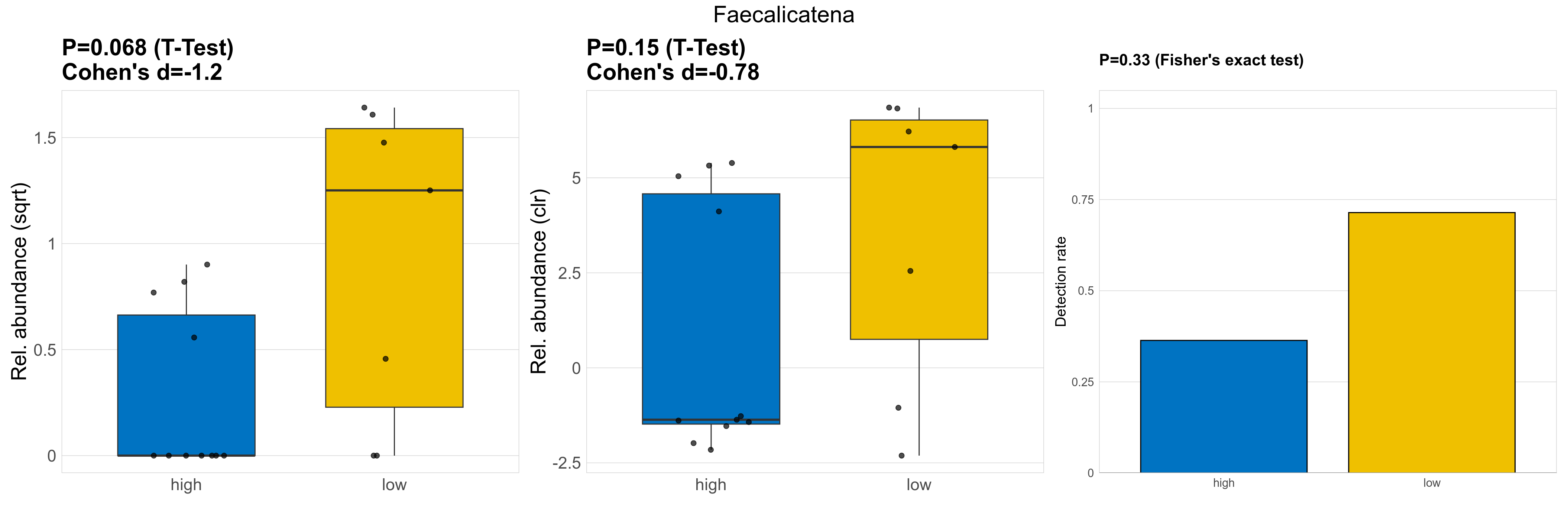
| Faecalicatena | Faecalicatena | 0.068 | 0.93 | 1 | -1.2 | 0.15 | 0.85 | 1 | -0.78 | 0.33 | 1 | 1 | 0.2 | 0.81 | 0.14 | 0.8 | 1.3 | 0.65 | 0.1 | 0.22 | 0 | 0.32 | 1.3 | 1.6 | 1.2 | 2.6 | 9 / 18 (50%) | 4 / 11 (36%) | 5 / 7 (71%) | 0.364 | 0.714 |
| Fusicatenibacter | Fusicatenibacter | 0.99 | 0.99 | 1 | 0.0072 | 0.72 | 0.94 | 1 | 0.19 | 1 | 1 | 1 | 0.7 | 0.92 | 0.62 | 0.92 | 4.9 | 4.3 | 3.2 | 4.1 | 3 | 3.2 | 4.7 | 3.8 | 5 | 0.2 | 16 / 18 (89%) | 10 / 11 (91%) | 6 / 7 (86%) | 0.909 | 0.857 |
| GCA-900066135 | GCA-900066135 | 0.64 | 0.95 | 1 | 0.24 | 0.49 | 0.94 | 1 | 0.34 | 0.64 | 1 | 1 | 0.5 | 0.88 | 0.65 | 0.92 | 0.27 | 0.1 | 0 | 0.11 | 0 | 0.15 | 0.092 | 0 | 0.18 | -0.26 | 7 / 18 (39%) | 5 / 11 (45%) | 2 / 7 (29%) | 0.455 | 0.286 |
| Gemmiger | Gemmiger | 0.69 | 0.95 | 1 | -0.23 | 0.84 | 0.94 | 1 | 0.11 | 1 | 1 | 1 | 0.78 | 0.94 | 0.77 | 0.95 | 2.9 | 2.6 | 2 | 2.1 | 1.7 | 1.6 | 3.3 | 2.2 | 4.1 | 0.65 | 16 / 18 (89%) | 10 / 11 (91%) | 6 / 7 (86%) | 0.909 | 0.857 |
| Holdemanella | Holdemanella | 0.32 | 0.93 | 1 | -0.6 | 0.35 | 0.85 | 1 | -0.52 | 0.53 | 1 | 1 | 0.35 | 0.84 | 0.36 | 0.85 | 2.6 | 0.43 | 0 | 0.16 | 0 | 0.55 | 0.84 | 0 | 1.5 | 2.4 | 3 / 18 (17%) | 1 / 11 (9.1%) | 2 / 7 (29%) | 0.0909 | 0.286 |
| Intestinibacter | Intestinibacter | 0.91 | 0.95 | 1 | -0.055 | 0.8 | 0.94 | 1 | -0.13 | 1 | 1 | 1 | 0.64 | 0.9 | 0.56 | 0.9 | 0.26 | 0.057 | 0 | 0.061 | 0 | 0.14 | 0.051 | 0 | 0.098 | -0.26 | 4 / 18 (22%) | 2 / 11 (18%) | 2 / 7 (29%) | 0.182 | 0.286 |
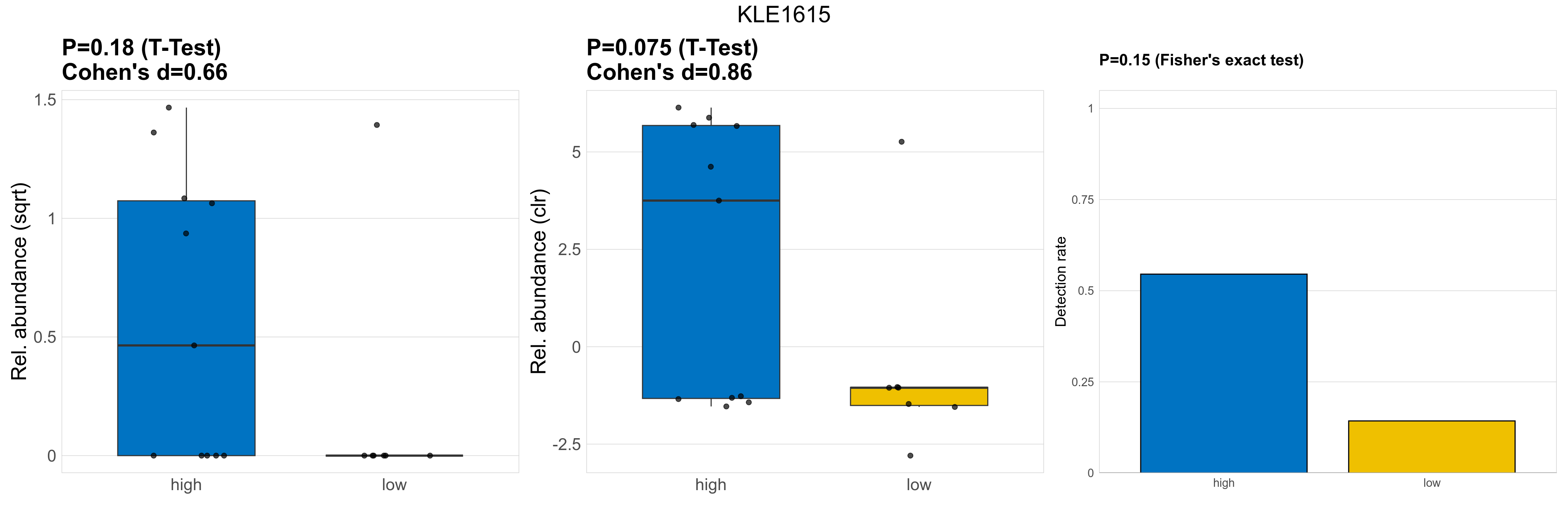
| KLE1615 | KLE1615 | 0.18 | 0.93 | 1 | 0.66 | 0.075 | 0.85 | 1 | 0.86 | 0.15 | 1 | 1 | 0.12 | 0.8 | 0.23 | 0.81 | 1.3 | 0.52 | 0 | 0.67 | 0.22 | 0.81 | 0.28 | 0 | 0.73 | -1.3 | 7 / 18 (39%) | 6 / 11 (55%) | 1 / 7 (14%) | 0.545 | 0.143 |
| Lachnospira | Lachnospira | 0.75 | 0.95 | 1 | -0.16 | 0.82 | 0.94 | 1 | -0.12 | 1 | 1 | 1 | 0.74 | 0.93 | 0.65 | 0.93 | 1.3 | 0.5 | 0 | 0.45 | 0 | 0.77 | 0.58 | 0 | 0.89 | 0.37 | 7 / 18 (39%) | 4 / 11 (36%) | 3 / 7 (43%) | 0.364 | 0.429 |
| Lactobacillus_B | Lactobacillus_B | 0.84 | 0.95 | 1 | -0.11 | 0.89 | 0.94 | 1 | 0.072 | 1 | 1 | 1 | 0.77 | 0.93 | 0.68 | 0.93 | 1.6 | 0.26 | 0 | 0.18 | 0 | 0.44 | 0.38 | 0 | 1 | 1.1 | 3 / 18 (17%) | 2 / 11 (18%) | 1 / 7 (14%) | 0.182 | 0.143 |
| Oscillibacter | Oscillibacter | 0.85 | 0.95 | 1 | -0.1 | 0.89 | 0.94 | 1 | 0.076 | 1 | 1 | 1 | 0.74 | 0.93 | 0.62 | 0.91 | 0.71 | 0.12 | 0 | 0.084 | 0 | 0.19 | 0.17 | 0 | 0.46 | 1 | 3 / 18 (17%) | 2 / 11 (18%) | 1 / 7 (14%) | 0.182 | 0.143 |
| Parabacteroides | Parabacteroides | 0.93 | 0.95 | 1 | 0.037 | 0.5 | 0.94 | 1 | -0.32 | 0.53 | 1 | 1 | 0.39 | 0.85 | 0.35 | 0.83 | 0.61 | 0.1 | 0 | 0.14 | 0 | 0.47 | 0.037 | 0 | 0.062 | -1.9 | 3 / 18 (17%) | 1 / 11 (9.1%) | 2 / 7 (29%) | 0.0909 | 0.286 |
| Phascolarctobacterium | Phascolarctobacterium | 0.76 | 0.95 | 1 | 0.13 | 0.84 | 0.94 | 1 | -0.09 | 1 | 1 | 1 | 0.6 | 0.89 | 0.48 | 0.89 | 0.71 | 0.16 | 0 | 0.22 | 0 | 0.64 | 0.06 | 0 | 0.1 | -1.9 | 4 / 18 (22%) | 2 / 11 (18%) | 2 / 7 (29%) | 0.182 | 0.286 |
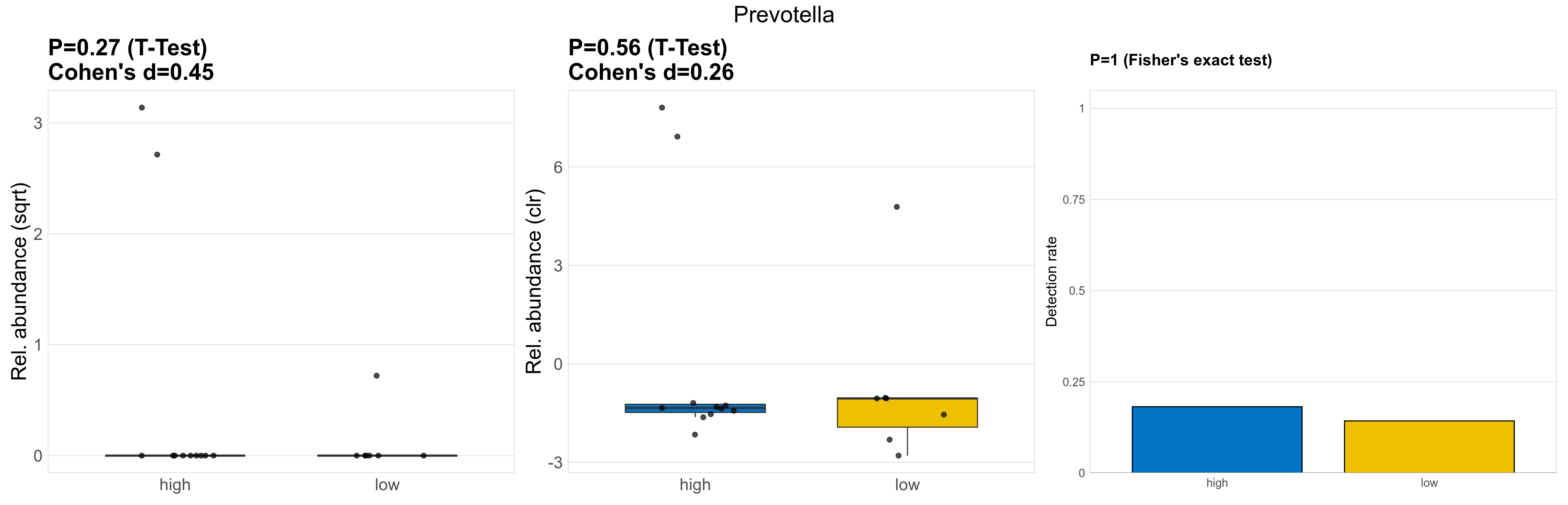
| Prevotella | Prevotella | 0.27 | 0.93 | 1 | 0.45 | 0.56 | 0.94 | 1 | 0.26 | 1 | 1 | 1 | 0.71 | 0.92 | 0.66 | 0.92 | 5.9 | 0.98 | 0 | 1.6 | 0 | 3.5 | 0.074 | 0 | 0.2 | -4.4 | 3 / 18 (17%) | 2 / 11 (18%) | 1 / 7 (14%) | 0.182 | 0.143 |
| Romboutsia | Romboutsia | 0.43 | 0.95 | 1 | 0.36 | 0.54 | 0.94 | 1 | 0.27 | 1 | 1 | 1 | 0.67 | 0.91 | 0.76 | 0.94 | 0.64 | 0.21 | 0 | 0.28 | 0 | 0.42 | 0.11 | 0 | 0.21 | -1.3 | 6 / 18 (33%) | 4 / 11 (36%) | 2 / 7 (29%) | 0.364 | 0.286 |
| Roseburia | Roseburia | 0.33 | 0.93 | 1 | -0.58 | 0.37 | 0.85 | 1 | -0.5 | 0.53 | 1 | 1 | 0.38 | 0.85 | 0.44 | 0.88 | 0.57 | 0.095 | 0 | 0.04 | 0 | 0.13 | 0.18 | 0 | 0.32 | 2.2 | 3 / 18 (17%) | 1 / 11 (9.1%) | 2 / 7 (29%) | 0.0909 | 0.286 |
| Ruminiclostridium_C | Ruminiclostridium_C | 0.3 | 0.93 | 1 | -0.6 | 0.3 | 0.85 | 1 | -0.56 | 0.33 | 1 | 1 | 0.29 | 0.83 | 0.33 | 0.84 | 0.23 | 0.064 | 0 | 0.032 | 0 | 0.073 | 0.11 | 0 | 0.18 | 1.8 | 5 / 18 (28%) | 2 / 11 (18%) | 3 / 7 (43%) | 0.182 | 0.429 |
| Ruminococcus_A | Ruminococcus_A | 0.87 | 0.95 | 1 | -0.079 | 0.58 | 0.94 | 1 | -0.27 | 0.63 | 1 | 1 | 0.45 | 0.86 | 0.54 | 0.9 | 0.97 | 0.43 | 0 | 0.47 | 0 | 0.81 | 0.37 | 0.16 | 0.48 | -0.35 | 8 / 18 (44%) | 4 / 11 (36%) | 4 / 7 (57%) | 0.364 | 0.571 |
| Ruminococcus_C | Ruminococcus_C | 0.74 | 0.95 | 1 | 0.16 | 0.81 | 0.94 | 1 | 0.12 | 1 | 1 | 1 | 0.81 | 0.94 | 0.79 | 0.95 | 1 | 0.46 | 0 | 0.51 | 0 | 0.6 | 0.38 | 0 | 0.53 | -0.42 | 8 / 18 (44%) | 5 / 11 (45%) | 3 / 7 (43%) | 0.455 | 0.429 |
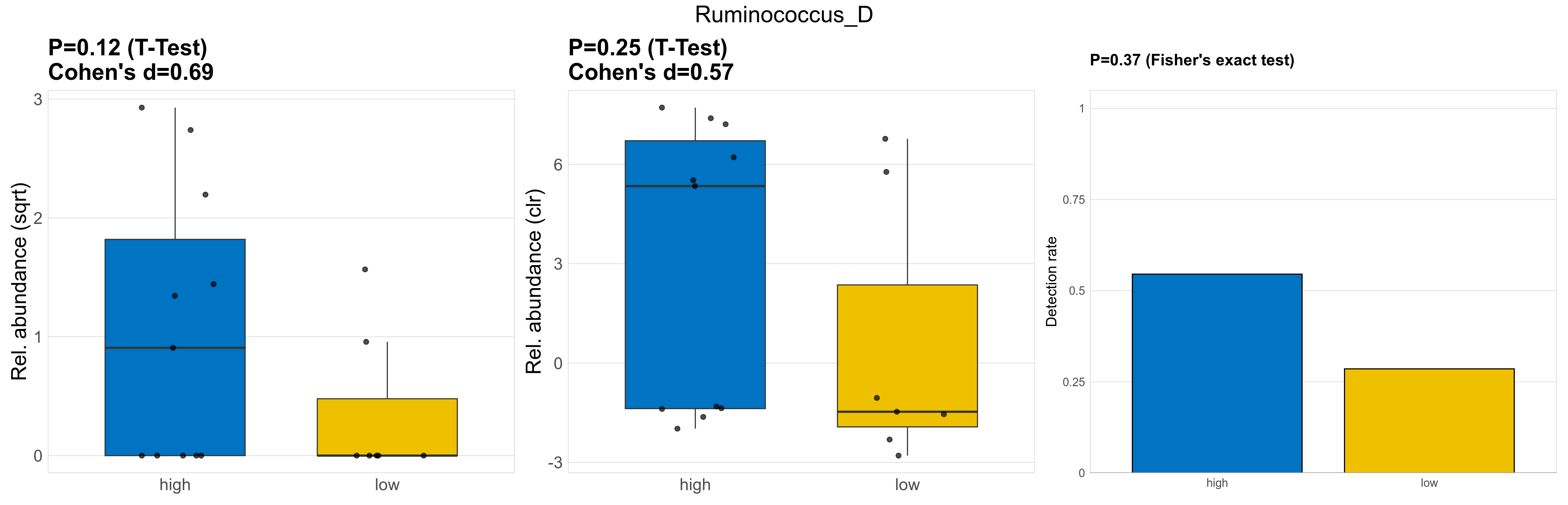
| Ruminococcus_D | Ruminococcus_D | 0.12 | 0.93 | 1 | 0.69 | 0.25 | 0.85 | 1 | 0.57 | 0.37 | 1 | 1 | 0.28 | 0.82 | 0.34 | 0.86 | 3.6 | 1.6 | 0 | 2.3 | 0.82 | 3.2 | 0.48 | 0 | 0.93 | -2.3 | 8 / 18 (44%) | 6 / 11 (55%) | 2 / 7 (29%) | 0.545 | 0.286 |
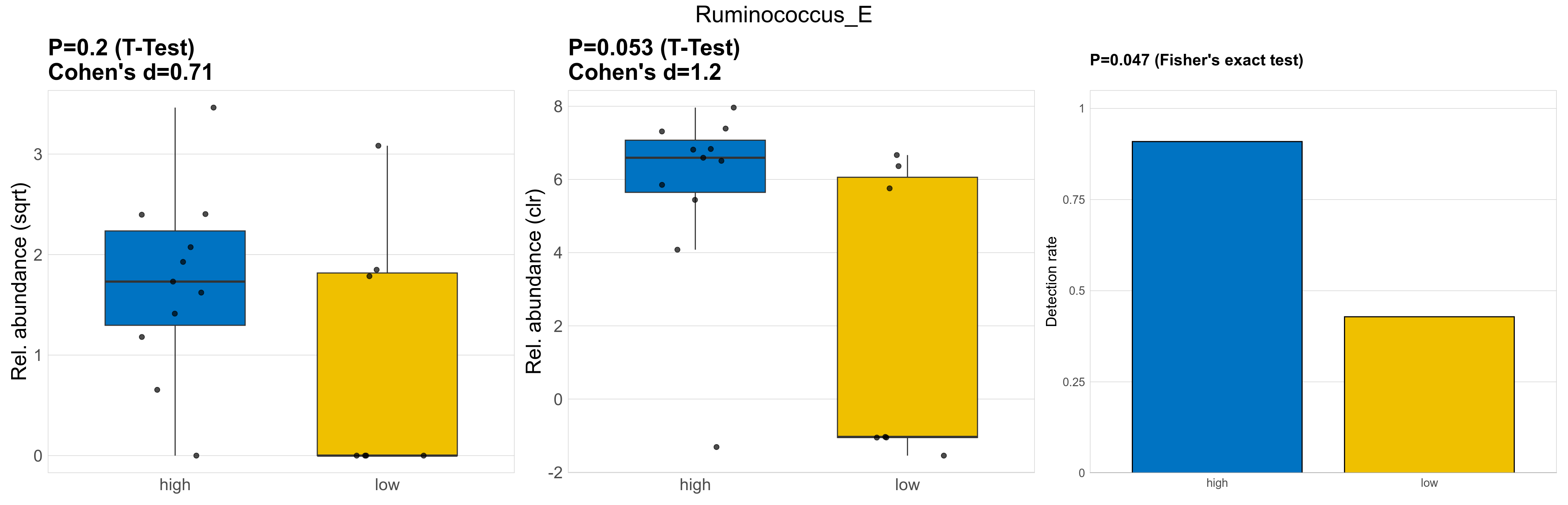
| Ruminococcus_E | Ruminococcus_E | 0.2 | 0.93 | 1 | 0.71 | 0.053 | 0.85 | 1 | 1.2 | 0.047 | 1 | 1 | 0.056 | 0.8 | 0.065 | 0.79 | 4.4 | 3.2 | 2.8 | 3.7 | 3 | 3.3 | 2.3 | 0 | 3.5 | -0.69 | 13 / 18 (72%) | 10 / 11 (91%) | 3 / 7 (43%) | 0.909 | 0.429 |
| Streptococcus | Streptococcus | 0.33 | 0.93 | 1 | -0.48 | 0.33 | 0.85 | 1 | -0.48 | 0.37 | 1 | 1 | 0.37 | 0.84 | 0.36 | 0.86 | 0.92 | 0.51 | 0.35 | 0.42 | 0 | 0.7 | 0.65 | 0.66 | 0.66 | 0.63 | 10 / 18 (56%) | 5 / 11 (45%) | 5 / 7 (71%) | 0.455 | 0.714 |
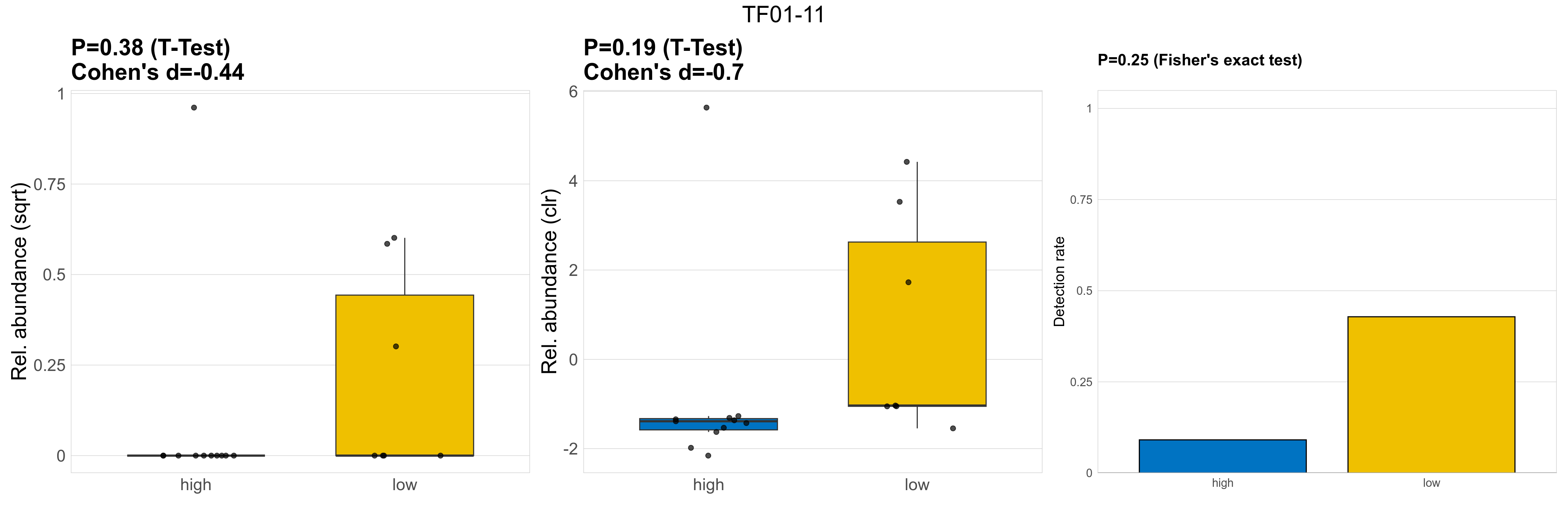
| TF01-11 | TF01-11 | 0.38 | 0.95 | 1 | -0.44 | 0.19 | 0.85 | 1 | -0.7 | 0.25 | 1 | 1 | 0.18 | 0.81 | 0.19 | 0.79 | 0.43 | 0.095 | 0 | 0.084 | 0 | 0.28 | 0.11 | 0 | 0.17 | 0.39 | 4 / 18 (22%) | 1 / 11 (9.1%) | 3 / 7 (43%) | 0.0909 | 0.429 |
| UBA11774 | UBA11774 | 0.6 | 0.95 | 1 | -0.27 | 0.54 | 0.94 | 1 | -0.31 | 0.63 | 1 | 1 | 0.46 | 0.87 | 0.46 | 0.88 | 0.96 | 0.32 | 0 | 0.27 | 0 | 0.6 | 0.4 | 0 | 0.68 | 0.57 | 6 / 18 (33%) | 3 / 11 (27%) | 3 / 7 (43%) | 0.273 | 0.429 |
| UBA7160 | UBA7160 | 0.9 | 0.95 | 1 | -0.074 | 0.62 | 0.94 | 1 | 0.24 | 1 | 1 | 1 | 0.63 | 0.9 | 0.66 | 0.92 | 0.54 | 0.12 | 0 | 0.077 | 0 | 0.15 | 0.19 | 0 | 0.5 | 1.3 | 4 / 18 (22%) | 3 / 11 (27%) | 1 / 7 (14%) | 0.273 | 0.143 |
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
Click here to open full-sized image in new window.
P Fisher's exact test: differences in detection rate were detected by Fisher's exact test.
P Welch's t-test (sqrt): Differentially abundant species were identified by Welch's t-test.
P Welch's t-test (clr): Differentially abundant species were identified by Welch's t-test.
The following plots present the distribution of the top most differentially abundant genera across all applied statistical analysis. Plots are ordered alphabetically.